Reference Documentation
Parallelism and compute structure
JuliaHub supports fully heterogeneous parallel compute. It uses the Distributed standard library to parallelize across workers on potentially many machines. Each worker can support multiple threads with the builtin Threads module. Each machine can optionally have a computational GPU attached to it for further acceleration with the CUDA package.
All of these modes of operation are fully supported and JuliaHub ensures that all machines in the cluster have the appropriate files and dependencies in place. This means, for example, that you do not need to addprocs or set the number threads yourself; your code should use scale-invariant constructs like pmap, @distributed and @threads or other higher-level abstractions like those for DifferentialEquations.jl.
JuliaHub also scales seamlessly from simple single-file scripts to whole applications with many thousands of lines of code, dependencies (both private and public), binary artifacts, and data. Your IDE will automatically detect all such dependencies, bundle them together, and ensure their availability on every node.
Project, Manifest and Artifacts
When running from VS Code or Juno, these are pre-populated based upon your active project.
When running ad-hoc code, you may choose them manually.
Outputs
The mechanism for reporting results from JuliaHub batch jobs is different depending on the version of JuliaHub Job Images you are using.
Total job results size is limited to 5GiB. Uploads exceeding this limit fail and the results will not be available for download.
To persist larger outputs, upload them as a Dataset from within the job instead.
Job Images Version 1
Set ENV["RESULTS"] to contain a simple JSON string to display certain values in the Output table. This is helpful for a handful of summary values to compare jobs at a glance on JuliaHub through the Details button. The contents of ENV["RESULTS"] are restricted to 1000 characters. If a longer value is set, it will be truncated.
You can further set the ENV["RESULTS_FILE"] to a local file on the filesystem that will be available for download after job completion. While there is only one results file per job, note that you can zip or tar multiple files together. The overall size of the results (the single file or the tar bundle) is limited to 5GiB. Upload of result exceeding that size is would fail, and they will not be available for download later.
Job Images Version 2
To output a simple JSON that contains values to be displayed in the output table, create a file at the path pointed to by the JULIAHUB_RESULTS_SUMMARY_FILE environment variable. This file must be a valid JSON file. The contents of this file are restricted to 1000 characters. If a longer value is set, it will be truncated.
Any file created under the folder pointed to by the JULIAHUB_RESULTS_UPLOAD_DIR environment variable will be uploaded once the job is completed. These will be available for download from the job results page. The overall size of the results is limited to 5GiB. Upload of result exceeding that size would fail, and they will not be available for download later.
Both JULIAHUB_RESULTS_SUMMARY_FILE and JULIAHUB_RESULTS_UPLOAD_DIR will be set for the batch job in JuliaHub environment.
Cluster design
Choose the number of cores and machines as appropriate:
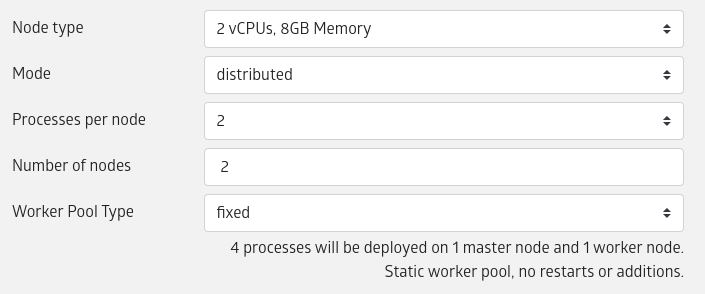
Select the node type that you wish to use. Node types determine the vCPU, memory, and type of GPU available on each node.
It is possible to either start a job with single Julia process or with multiple Julia processes.
- To start a job with single Julia process, select
single-processfor "Mode". - To start a job with multiple Julia processes, select
distributedfor "Mode".
The vCPU and memory selections will determine the node type/size on which the job will be run.
The actual number of Julia processes that will be started depends on the selection for processes per node and number of nodes, such that total number of Julia processes = number of nodes * processes per node.
Note that one Julia process will always be designated to be the master and the remaining would be worker processes.

The worker pool type of a distributed job can be one of fixed or elastic.
A job with fixed worker pool would wait for all (or a configured minimum) number of workers to join before the job code is executed. Once the job code starts executing, no more (delayed) workers are allowed to join. Also if any worker fails during execution it would not be restarted.
A job with an elastic worker pool would not wait for workers before starting to execute the job code. But it would allow workers to join any time while the job code is running. And if any worker fails during execution they would be restarted.
In the JuliaHub environment, spawning of worker processes is managed internally by the JuliaHub platform. The user code only needs to use certain distributed Julia packages and functions to interact with the workers.
In the version 1 of the JuliaHub Job images, the JuliaHub cluster manager is injected automatically into the environment of the job code. In the version 2 of the Job images, the user code needs to explicitly add the JuliaHubDistributed.jl package to the project environment and import it in the code.
Using JuliaHubDistributed.jl with JuliaHub Job Images Version 2
The JuliaHubDistributed.jl package is registered in the JuliaHubRegistry and can be accessed using your JuliaHub credentials. It also provides a mock distributed computing environment for local development. Though it does not have the same APIs as a regular Julia cluster manager, it does provide a similar experience regarding launching and managing workers. TheElastic submodule has APIs needed to work with the JuliaHub Elastic infrastructure.
Using this package with JuliaHub is really simple. Just add it to your project and import it in your code. Here's a snippet of code that shows how to use it:
using JuliaHubDistributed
# start the distributed mode
JuliaHubDistributed.start()
# Continue doing stuff that is needed to be done only on master...
# When workers are needed, ensure that they are available.
# This will ensure that the distributed environment as specified
# for the job (worker count, distributed mode, etc.) is ready to be used.
JuliaHubDistributed.wait_for_workers()
# Do distributed work...Alternatively, an option can be passed to start to wait for workers to be available before returning.
using JuliaHubDistributed
# start distributed mode and wait for minimum number of workers to be available
JuliaHubDistributed.start(ensure_min_workers=true)
# Do distributed work...Using JuliaHubDistributed.jl in local development
Code written using this package should work both locally and on JuliaHub. While on JuliaHub, the JuliaHub machinery provisions workers on the cloud, on the local machine, the package provisions workers on the same machine as the master process. This allows for local development and testing of code that uses this package on the local machine.
For local development, the following environment variables are needed to configure the distributed environment:
JULIAHUB_NWORKERS: Number of workers. A value of 0 (default) indicates non distributed workload.JULIAHUB_CLUSTER_COOKIE: Cluster cookie to use as shared secret.
The following optional environment variables can be used to configure the distributed environment:
JULIAHUB_ELASTIC_WORKERS: Whether workers are elastic. This is "false" by default.JULIAHUB_MIN_WORKERS_REQUIRED: Minimum number of workers required. By default this is set to the same value asJULIAHUB_NWORKERS.
Elastic worker pools
An elastic worker pool has the advantage of quick start times and is resilient to failures. However they may not be suitable for all types of programs.
Programs that do not depend on workers being initialized in a specific way should already be compatible to the elastic mode. The only change that they may need is where the code needs a certain minimum number of workers to work, they may need to add a check. This extra check is needed only when running your code on the Version 1 Job Images. The version 2 job images already incorporate this check into the start and wait_for_workers APIs as illustrated above. To add this check, use the timedwait API. E.g.:
using Distributed
@assert :ok === timedwait(120.0; pollint=5.0) do
nworkers() >= min_workers_required
endTo use the Elastic module methods, you need to import it first. In the version 1 job images, this can be done as follows:
using Main.JuliaRunJob.ElasticIn the version 2 job images, this can be done as follows:
using JuliaHubDistributed.ElasticPrograms that require specific initialization steps to be done on the worker, typically done via one or more @everywhere macro invocations in the beginning, can be adapted to be elastic mode compatible using certain (experimental) APIs provided in the JuliaHub environment. Essentially it involves using the @init_workers macro provided in the JuliaRunJob.Elastic module instead of @everywhere. E.g.:
Elastic.@init_workers begin
function docalc(x)
# ...
x*10
end
endIf the program makes use of pmap, use the one provided in the JuliaRunJob.Elastic module instead. E.g.:
A = [1,2,3,4,5,6,7,8,9,10]
Elastic.pmap(A) do x
return docalc(x)
endOther Distributed APIs that accept a worker pool can also be used, by explicitly providing the elastic pool instance. The Elastic.pool() API provides a reference to the elastic worker pool.
Logging
While running your batch job, live logs are available. Note that it can take a few minutes to launch the machines (longer for GPU machines) and logs to appear. The logs displayed in the job logs viewer are searchable through dynamic filters, with additional information available if you use the builtin logging module and related macros (like @info, @warn, and friends).
The Version 1 JuliaHub Job Images inject and enforce logging via JuliaHub structured logging library. It is transparent and the only way applications can log.
With Version 2 of the JuliaHub Job Images, applications are free to use any logging library. However some applications seeking tighter integration with JuliaHub features (e.g. progress reporting) can still choose to use the JuliaHub structured logging library. They can do so by adding the JuliaHubLogging.jl package to their project and using the logger from it. The JuliaHubLogging package is available in the JuliaHubRegistry registry. The logger can be used as follows:
using JuliaHubLogging, Logging
...
logger = JuliaHubLogging.prepare_logger(...)
with_logger(logger) do
@info "message"
...
endPlease check with your administrator to know the version of images enabled for your installation.
Preferences and Payments
The "Preferences" and "Payments" pages for the account can be accessed by clicking on the account settings icon in the upper right corner of the screen.
The menu can also be used to toggle between a light and dark theme for the web interface.
Secrets
Jobs can have access to secrets. Secrets can store sensitive information encrypted and make them available to your job at run time. Secrets are associated with namespaces. Namespace can either be user or project.
Any code running inside the job — including third-party packages — can read the same secrets the job has access to. See Authentication tokens inside jobs for the trust model that applies to job code.
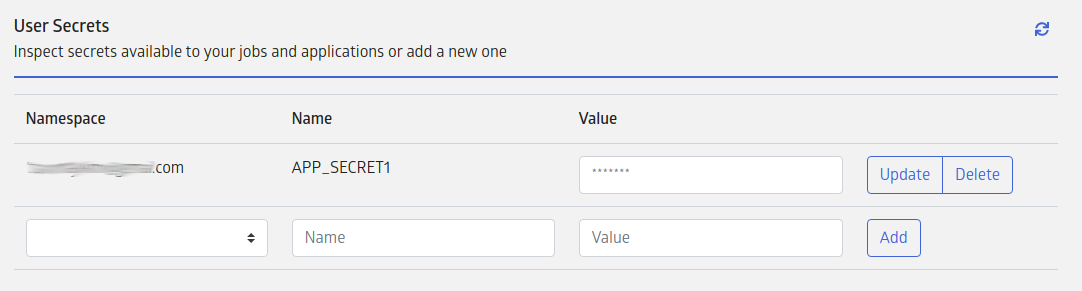
Secrets in user namespace are private to the user. They can be configured on the account preferences page. The secrets management section will list existing secrets if any are configured.
Secrets created in the project namespace can only be accessed by jobs that run in the context of that project. Project secrets can be configured from the project management screen.
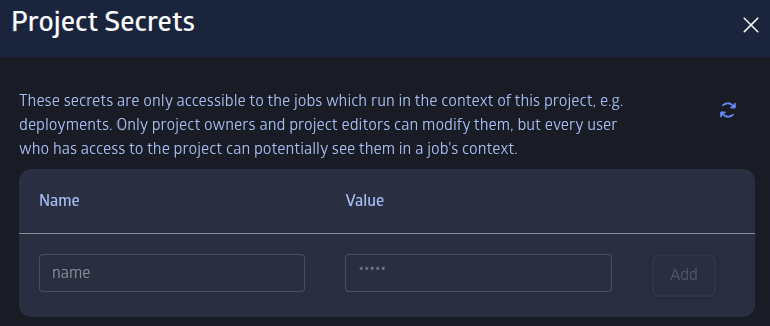
Depending on the version of JuliaHub installation and JuliaHub Job Images you are using, the API may be different. Please check with your administrator regarding the exact version numbers.
Job Images Version 1
The JuliaRunJob module should already be injected into the julia environment and loaded at top level in the runtime.
You could use the get_secret API to access secrets from the user's own namespace: secretvalue = JuliaRunJob.get_secret(secretname).
There is also a secrets manager get API that can be used to access secrets from other namespaces a user may have access to. For the v1 APIs, the user's email address is used as the user namespace, and the string project: is prefixed to the project name to form the project namespace.
secretvalue = JuliaRunJob.get(
JuliaRunJob.SECRETS_MANAGER[],
joinpath(base64encode(secrets_namespace), secretname)
)Where:
SECRETS_MANAGER[]provides a handle to the secrets manager context for the jobsecretnameis the name of the secret to accesssecrets_namespaceis the namespace in which the secret exists
It is important to note that these APIs are currently not supported for Julia IDE jobs, thus they cannot be called in VS Code. Users can use these APIs in Julia code, which can then be submitted as input for Standard Batch jobs.
Job Images Version 2
The secrets APIs have been made available as a separate package JuliaHubSecrets.jl registered in the private JuliaHubRegistry. As a JuliaHub user, you should be able to add the registry to your Julia environment and install JuliaHubSecrets, all using your JuliaHub authentication. Include JuliaHubSecrets in your project manifest and use the APIs as:
using JuliaHubSecrets
secretvalue = JuliaHubSecrets.fetch_secret(secretname)Note that unlike the v1 APIs, the v2 APIs do not require the namespace to be specified. The v2 API fetches the secret value for the specified secret from either the user namespace or the project namespace in that order. The v2 APIs can be used in both Julia batch jobs and Julia IDE jobs. These APIs can also be used in local Julia sessions, but the secrets will be fetched from the local environment, wherein an environment variable with name same as the secret name should be set.
Billing
Set your credit card information in the Payments settings:
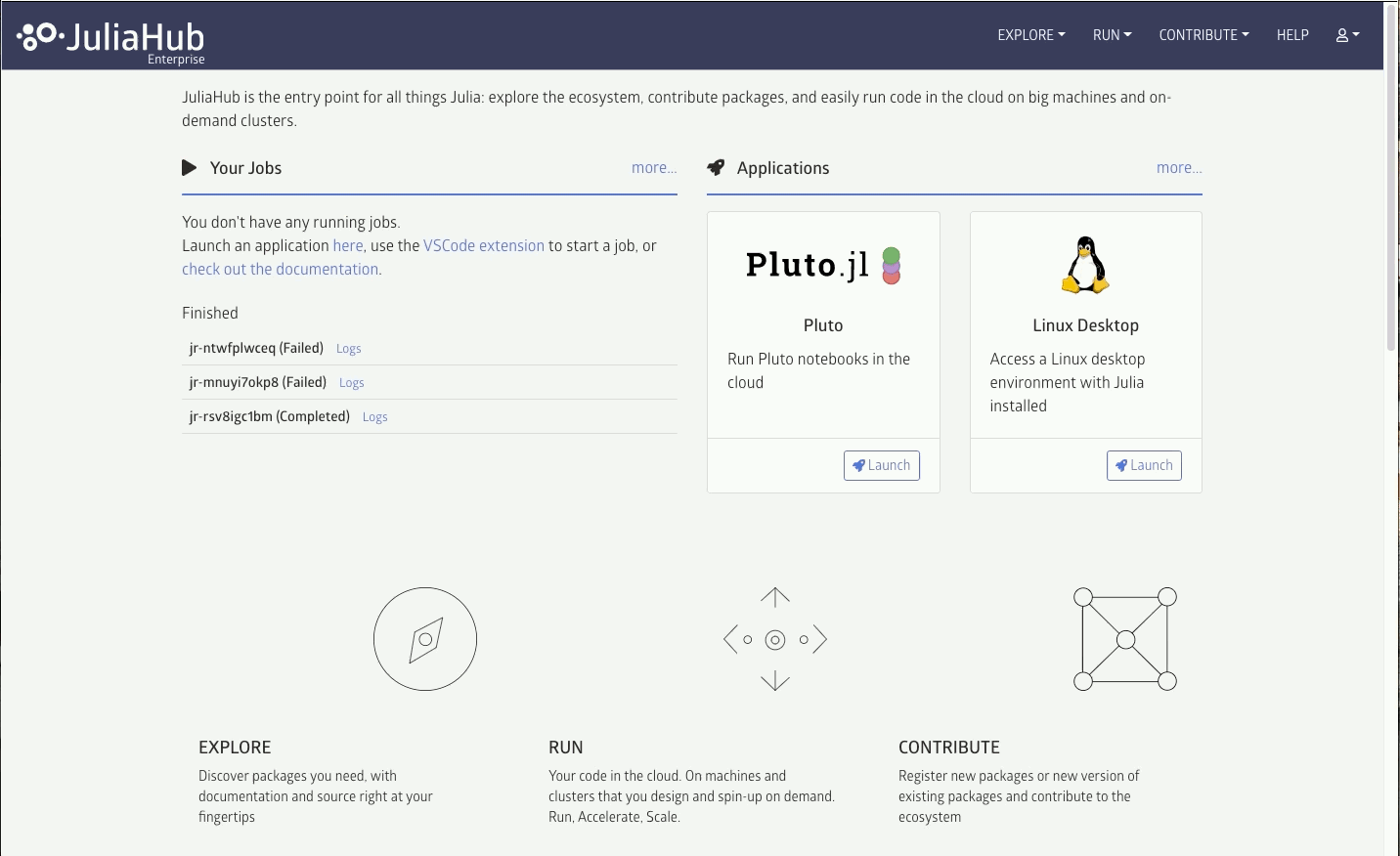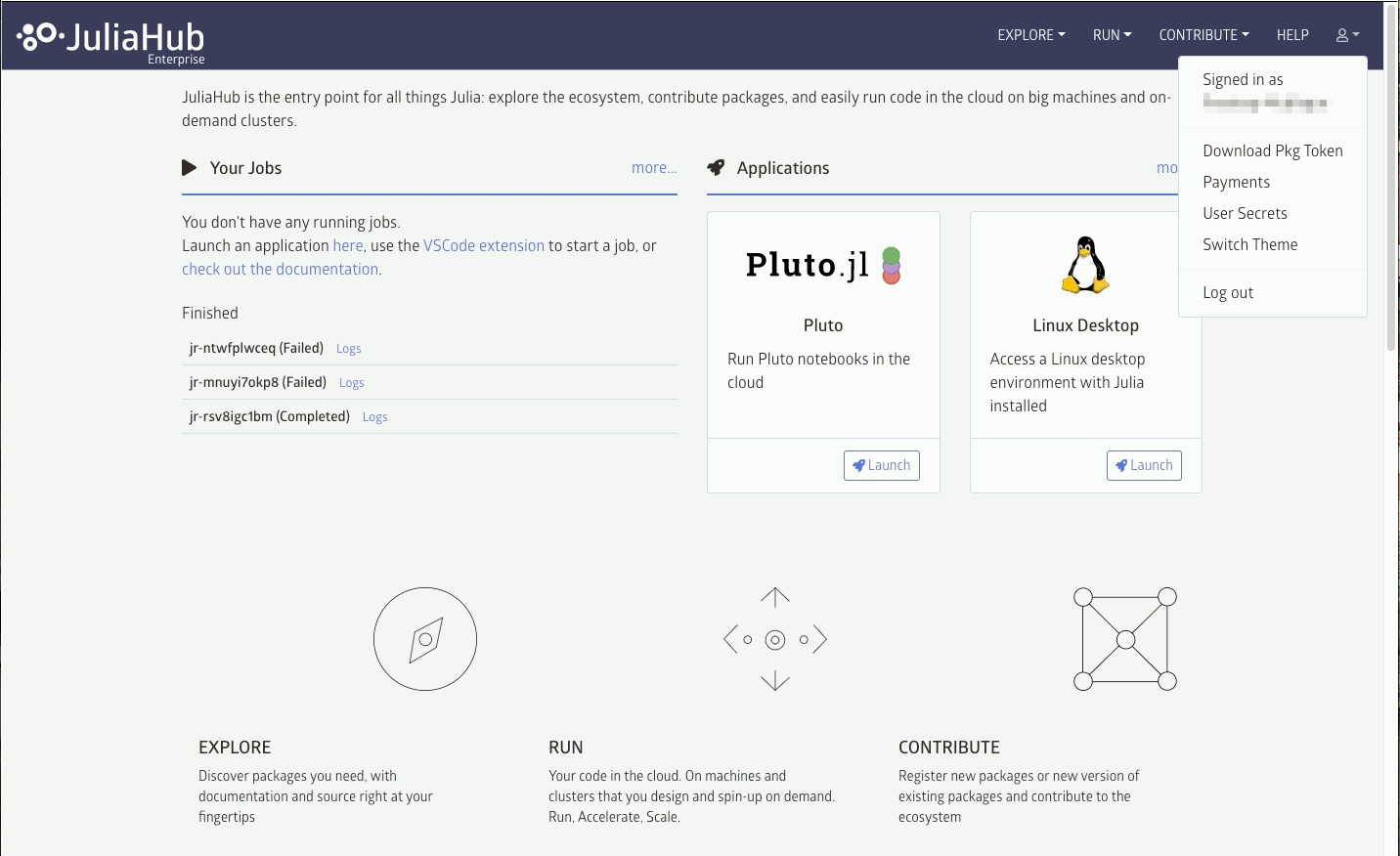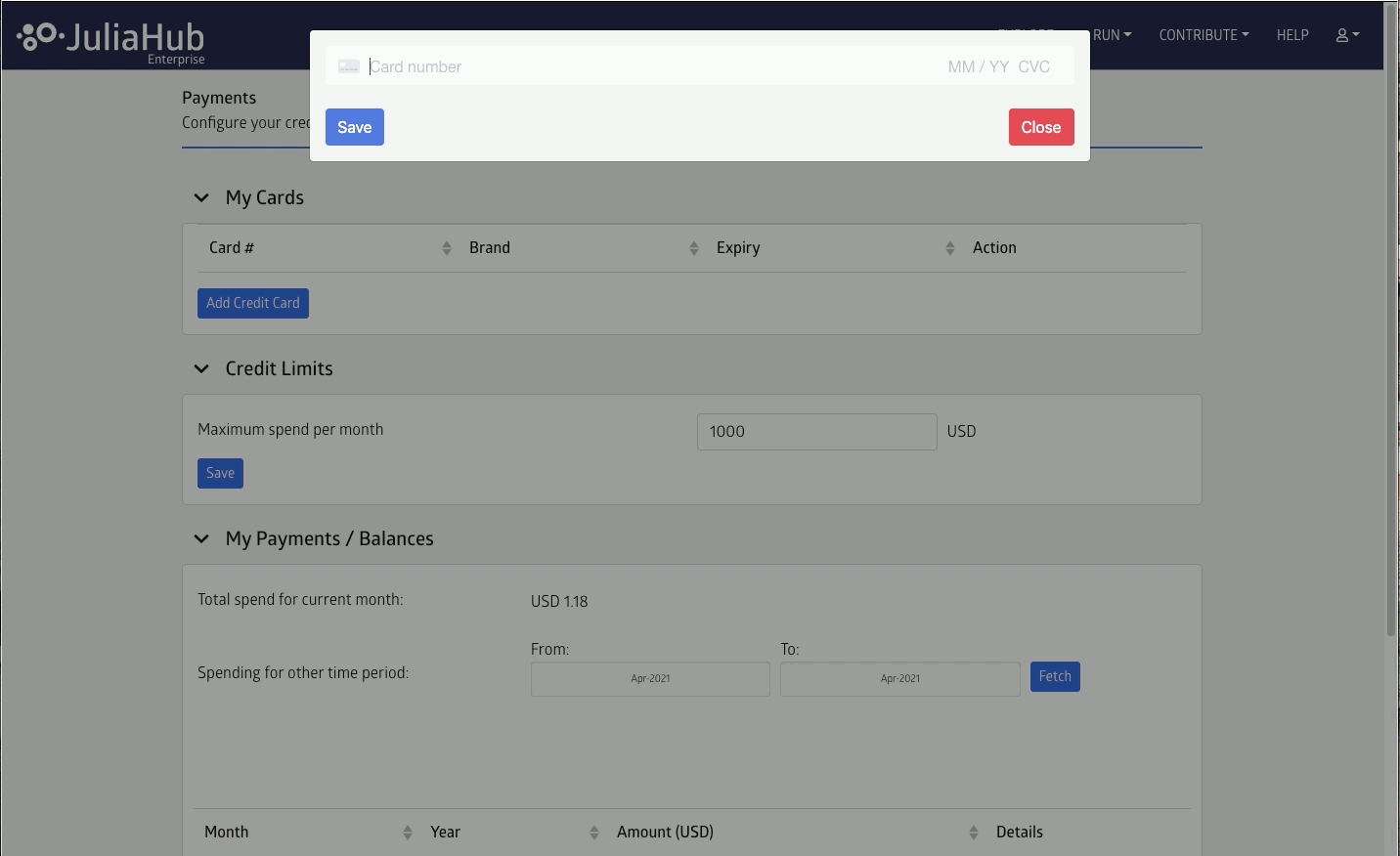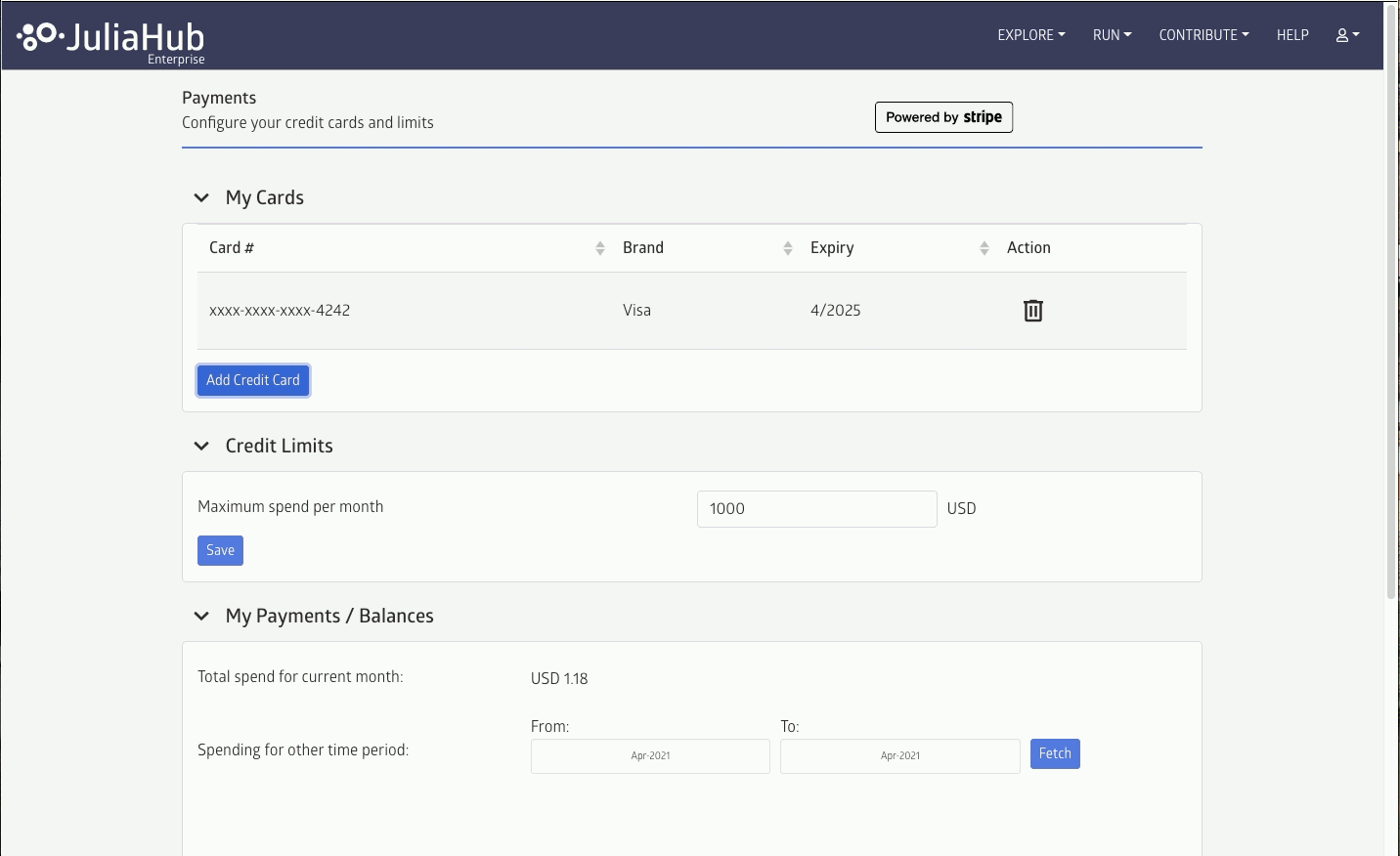
Billing is done at per-second interval, but with a minimum 10 minutes per job. You may set the maximum time or cost for any given job, but note that jobs that exceed that limit will be killed without storing any outputs (although logs will still be available).
Users and Groups
A JuliaHub user represents an authenticated entity that can access JuliaHub resources. Users are authenticated via an identity provider, which must be configured during installation to be able to use JuliaHub. The identity provider is usually owned by the enterprise where the installation exists.
Authorization for JuliaHub resources can be configured for authenticated users. They can also be configured for groups of users. Groups are simple collections of users. Nesting of groups is not possible. A user can be a member of multiple groups.
Groups can come from multiple sources, which are also sometimes called "realms". The enterprise identity provider can be a source or realm. This is referred to as the "site" or "IDP" realm in JuliaHub. There also exists a JuliaHub internal realm, which comes with certain pre-defined groups - "admins", "customeradmins" (customer admins), "users" and "anon". This is referred to as the "juliahub" realm. All authenticated users are automatically members of the "users" group in the "juliahub" realm. A user can not be un-assigned from the "users" group. Any unauthenticated access is treated as being done by the "anon" group. From authorizations perspective, any authorization granted to the "anon" group is applicable to all, while any authorization granted to the "users" group is applicable to all authenticated users.
Users and Groups Administration
Actions that can be performed on users and groups and their memberships are available in the "Users and Groups" section of the administration user interface. This section is only available to users who have the "admins" or "customeradmins" (customer admins) group membership.
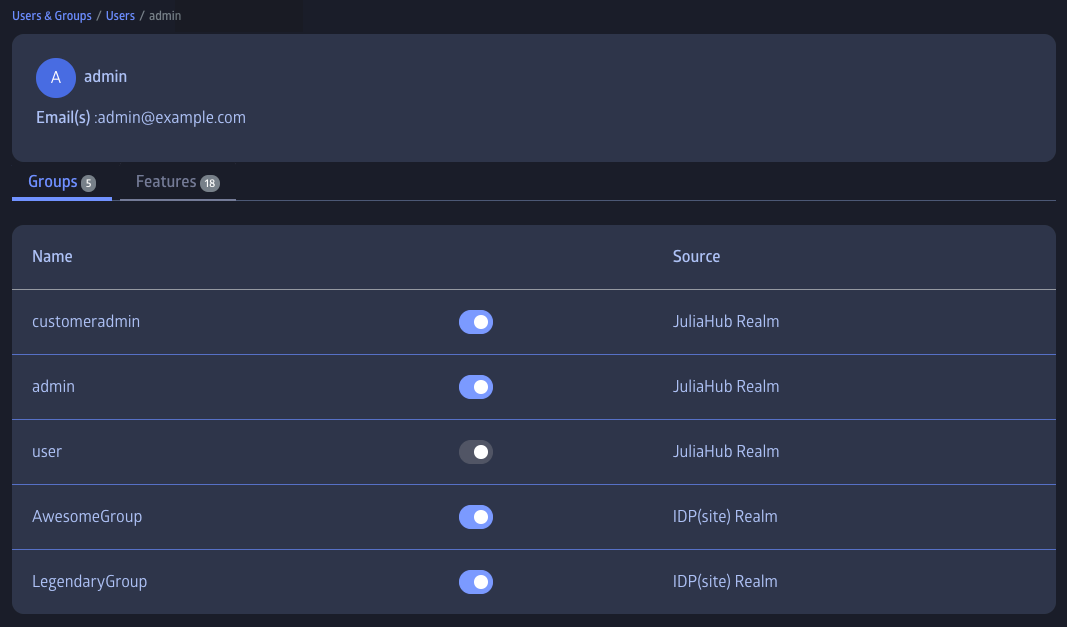
The "admins" are allowed to perform all actions. Only admins can assign users to the "admin" group. Customer admins can assign users to the "customeradmins" (customer admins) group and any other group that is part of the "site" realm, but are not allowed to do any manipulations that refer to the "admin" group.
While certain JuliaHub features are accessible to all users, some may require authorization. The "Users and Groups" administration section also allows admins and customer admins to assign features to individual users.
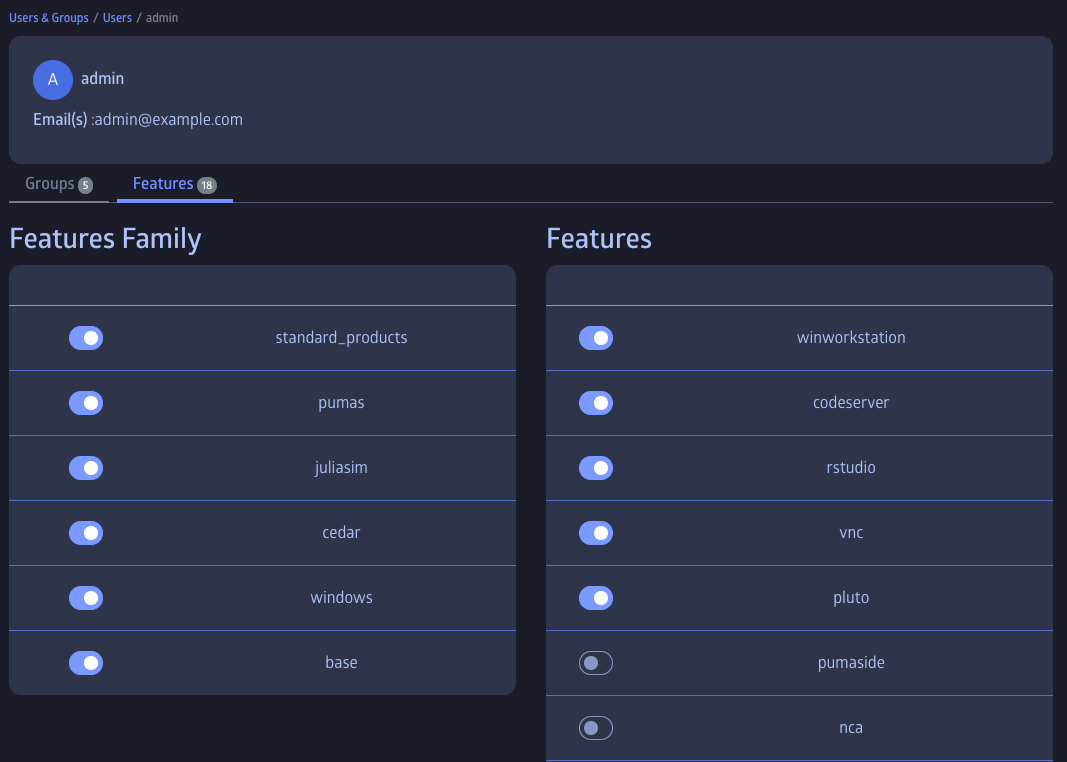
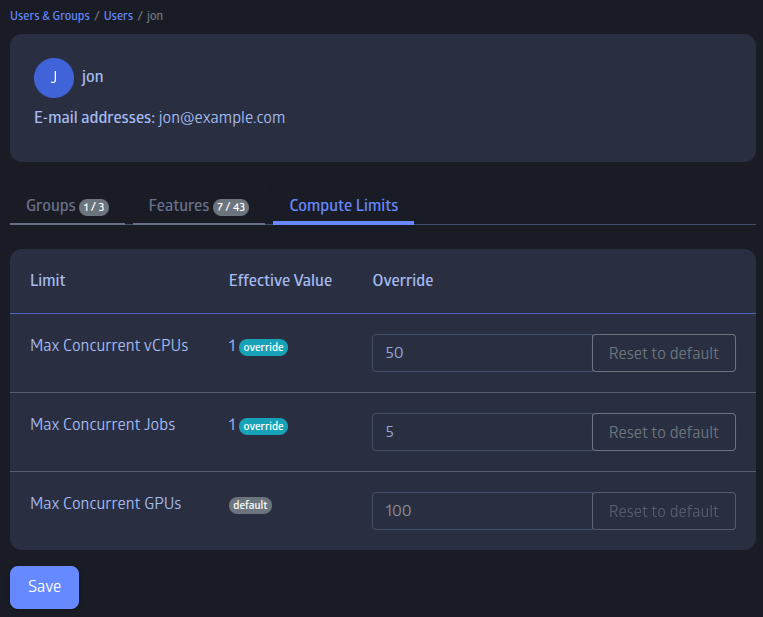
Administrators can also configure per-user compute limits from the "Compute Limits" tab in the user details view. This allows setting maximum concurrent jobs, GPUs, and vCPUs for individual users. When a per-user override is not set, the platform-wide global default applies. Users who attempt to submit a job that would exceed their limit will receive an error message prompting them to contact their administrator.
Permissions for users and admins
Here's a brief reference table of actions which users and administrators can perform, according to the JuliaHub specification v2.0:
| JuliaHub Platform Action | User | Administrator |
|---|---|---|
| Access platform | Yes | Yes |
| View Julia packages and applications | Yes | Yes |
| Search documentation | Yes | Yes |
| Compute job support | Yes | Yes |
| Start interactive jobs | Yes | Yes |
| Start distributed jobs | Yes | Yes |
| Stop running jobs started by the user themself | Yes | Yes |
| Stop running jobs started by other users | No | No |
| Extend timeout of running jobs started by the user themself | Yes | Yes |
| Extend timeout of running jobs started by other users | No | No |
| View job history of jobs started by the user themself | Yes | Yes |
| View job history of jobs started by other users | No | No |
| Download job logs and results of job started by the user themself | Yes | Yes |
| Download job logs and results of job started by other users | No | No |
| Dataset support | Yes | Yes |
| Upload datasets | Yes | Yes |
| View storage metadata for datasets uploaded by the user themself | Yes | Yes |
| View storage metadata for datasets uploaded by other users | No | No |
| View and access uploaded datasets marked public | Yes | Yes |
| View and access uploaded datasets marked private and uploaded by the user themself | Yes | Yes |
| View and access uploaded datasets marked private and uploaded by other users | No | No |
| Delete datasets uploaded by the user themself | Yes | Yes |
| Delete datasets uploaded by other users | No | No |
| Change dataset visibility for datasets uploaded by the user themself | Yes | Yes |
| Change dataset visibility for datasets uploaded by other users | No | No |
| View Julia package usage for all users | No | Yes |
| View platform audit logs | No | Yes |
| View platform job usage summary | No | Yes |
| View Julia package analytics | No | Yes |
| Modify JuliaHub Platform configuration such as: | No | No |
| - Logo | No | No |
| - Notebook pinning | No | No |
| - Customizing home page | No | No |
| - Default machine configuration | No | No |
| - Default timeout | No | No |
| - Managing private Julia package registries | No | No |
| - Customize Project editing workflow options and default | No | No |
| Manage platform policy: create, modify, delete | No | Yes |
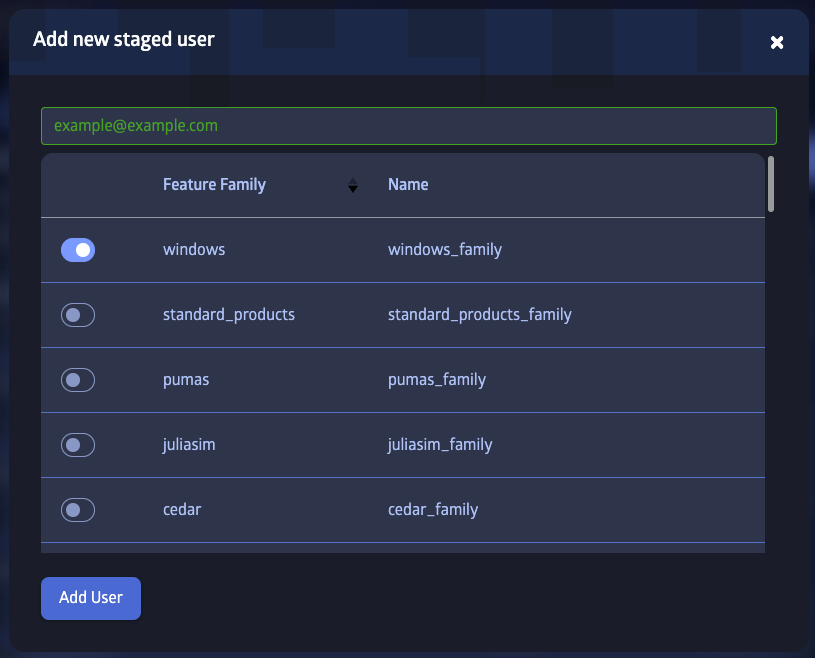
Staged Users
Staged users are users who have been invited to join JuliaHub but have not yet accepted the invitation. They are assigned special placeholder accounts, which let admins and customer admins pre-configure their accounts to a certain extent, e.g. staged accounts can be preconfigured with access to features. Staged users are not allowed to access JuliaHub resources. They can be deleted by admins or customer admins before they join. A staged user gets promoted to a regular user when they accept the invitation and log in to JuliaHub the first time. Regular users can not be deleted, so any resources associated with them and remains available in the system even if they can not log in to JuliaHub.
The "Users and Groups" section of the administration user interface allows admins and customer admins to create and manage staged users.
Programmatic Authentication
In order to communicate with the JuliaHub backend servers (e.g. to access datasets), a Julia session must have access to a user-specific authentication token. For this, JuliaHub reuses Julia's built-in support for authenticating with a package server.
In order for this to work, Julia must be configured to use the JuliaHub package server, and an auth.toml file, containing the user-specific authentication token, must be present in the ~/.julia directory.
In the different JuliaHub applications, this is generally all set up automatically. However, to access JuliaHub from external machines, this can be configured manually by
- Downloading the
auth.tomlfile from the preference page on JuliaHub and saving it to.julia/servers/juliahub.com/auth.toml. - Configuring Julia to use the JuliaHub package server at
https://juliahub.com/(e.g. by settingJULIA_PKG_SERVERasJULIA_PKG_SERVER="https://juliahub.com/", or directly in the JuliaHub VSCode IDE plugin).

Note that the token in auth.toml expires in 24 hours if it is not used, and must be downloaded again. However, any operation in the Julia package manager that talks to the package server (like updating a package or the registry) will refresh the token automatically.
Authentication tokens inside jobs
When you launch a job on JuliaHub, an authentication token is provisioned into the job environment so that code running in the job can call back into the JuliaHub API on your behalf — for example, to read datasets, write dataset versions, submit follow-on jobs, or fetch secrets. The token is mounted into the job container at /var/run/secrets/jobsecrets/ and is refreshed by a sidecar for the duration of the job.
This token represents your user identity. Any code that runs inside a job — including third-party packages installed from a registry, scripts pulled in at runtime, or anything else your job's startup pulls into its environment — runs as you and has the same access to the JuliaHub API as you do from your own machine. That includes:
- Submitting new jobs (and being billed for them).
- Reading, writing, and deleting datasets you own or have write access to.
- Requesting temporary cloud credentials for datasets you can already access.
- Fetching secrets from namespaces you have access to.
This is by design. Jobs that orchestrate other jobs, write results back to datasets, or pull configuration from secrets are first-class workflows on the platform, and they require the token to act as the submitting user.
The practical consequence is that the trust boundary for a job is the code you choose to run in it, not the runtime. Before submitting a job, treat its dependency set the same way you would treat code you'd run on your laptop with your auth.toml present: prefer packages from registries and versions you trust, pin or review what you depend on, and avoid pulling arbitrary code into the job at runtime. If a job's code is malicious or compromised, it can do anything you can do via the JuliaHub API for the lifetime of the token.
If your workflow needs narrower-than-user access for a specific resource — for example, read-only access to a single dataset from a job — prefer the delegated cloud credentials issued via the dataset APIs, which are scoped to the specific dataset rather than to your full identity.
Connecting VSCode IDE to JuliaHub
Make sure you've got the main Julia plugin installed from the VSCode marketplace as discussed in the vscode Julia extension documentation.
Next, install the JuliaHub plugin from the VSCode marketplace. Once installed, use the "show JuliaHub" command to open the JuliaHub pane.
The JuliaHub plugin uses the package server setting from the Julia plugin. You'll need to set this to https://juliahub.com:
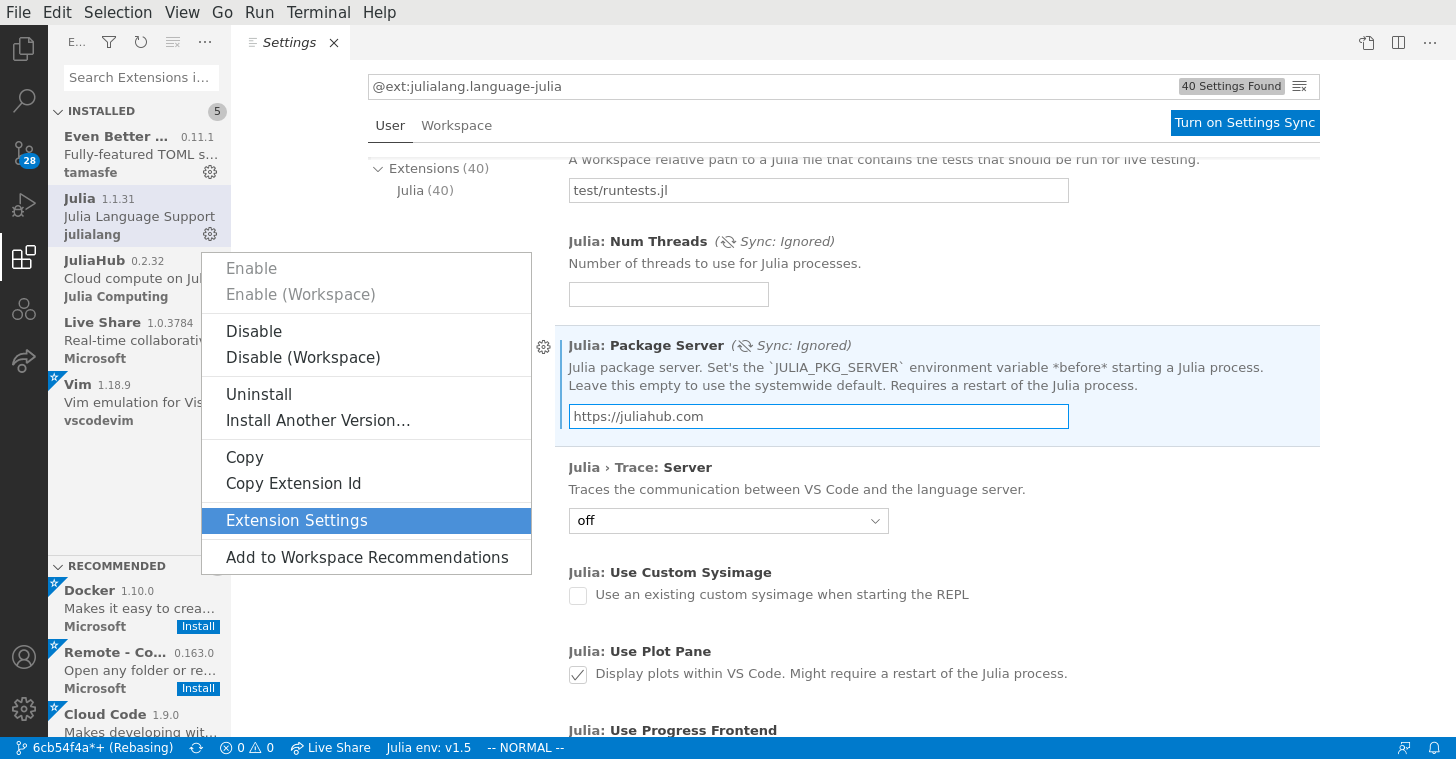
If need be, the VSCode plugin will open a browser window to authenticate with JuliaHub and then automatically acquire the auth.toml file.
Migrating Batch Programs for JuliaHub Job Images Version 2
The following changes are required to migrate batch programs to use JuliaHub Job Images Version 2. The packages referred to below are available in the JuliaHubRegistry. As a JuliaHub user, you should be able to add the registry to your Julia environment and install the packages.
- Secrets APIs:
- Add
JuliaHubSecretsto Project.toml, update Manifest.toml. ImportJuliaHubSecretsin code. - Search for method invocations of
JuliaRunJob.getorget_secret - Replace those with
JuliaHubSecrets.fetch_secret(...)
- Add
- Datasets: Add
JuliaHubDatato Project.toml, update Manifest.toml. ImportJuliaHubDatain code. - Outputs:
- If code is creating output files and setting environment variable
RESULTS_FILEorRESULTS_FILE_TO_UPLOAD, replace with creating the result files in the folder specified byJULIAHUB_RESULTS_UPLOAD_DIRenvironment variable instead. - If code is setting environment variables
RESULTSorOUTPUTS, replace with creating a JSON file at the path specified by as theJULIAHUB_RESULTS_SUMMARY_FILEenvironment variable instead.
- If code is creating output files and setting environment variable
- Distributed:
- Add
JuliaHubDistributedto Project.toml, update Manifest.toml. ImportJuliaHubDistributedin code. - Code that uses elastic worker pools should also import
JuliaHubDistributed.Elastic. They can continue to useElastic.@init_workersandElastic.pmapas usual. - Invoke
JuliaHubDistributed.start(). This method will return immediately, but will start the distributed workers, and connect them to the cluster in the background. The number of workers is what is specified in the job launch request. - Invoke
JuliaHubDistributed.wait_for_workers()after doing master specific activities and just before starting to use the workers. This waits until the workers join the cluster and are initialized. Note that when job is launched with elastic worker pools, this becomes a no-op, the elastic compute methods are either agnostic to worker availability or internally check for availability where needed. - Code written using JuliaHubDistributed.jl will also work on local development machines. It will launch workers on the same machine as the master. This is useful for testing and debugging.
- Add
- Logging: If there is need to use JuliaHub structured logging, add
JuliaHubLogging.jlto Project.toml and use the logger from it. E.g.: - Export Ports: If the code fetched the exposed network port using the
PORTenvironment variable, replace it withJULIAHUB_APP_PORTinstead.
using JuliaHubLogging, Logging
...
logger = JuliaHubLogging.prepare_logger(...)
with_logger(logger) do
@info "message"
...
end