PDE control
This tutorial solves Poisson-style equation and adds an LQR controller to control the solution in the center of the domain.
We finish off by simulating the closed-loop system with a sinusoidal disturbance.
Outline
- Define the model and find a steady-state solution without disturbances.
- Discretize the model and linearize the discretized system to obtain a linear statespace model.
- Design an LQR controller for the linear system.
- Simulate the dynamic PDE with the LQR controller and a disturbance.
Define PDE system
The PDE system we will control is a Possion-style system with added inputs, one controlled input and one disturbance input. Both of these inputs act through "influence functions" which are chosen to be Gaussian blobs with a very limited support.
using ModelingToolkit, OrdinaryDiffEq, MethodOfLines, ControlSystems, Plots, ControlSystemsMTK, Interpolations, SteadyStateDiffEq
@parameters x y t
@variables u(..) a(t)=0
Dxx = Differential(x)^2
Dyy = Differential(y)^2
Dt = Differential(t)
Ainfluence(x,y) = exp(-((x-0.5)^2 + (y-0.5)^2)/0.1^2) # Actuator influence function
Dinfluence(x,y) = exp(-((x-0.3)^2 + (y-0.5)^2)/0.1^2) # Disturbance influence function
# Boundary conditions
bcs = [
u(0,x,y) ~ 0.0,
u(t,0,y) ~ 0.0, u(t,1,y) ~ 0.0,
u(t,x,0) ~ 0.0, u(t,x,1) ~ 0.0
]
# Space and time domains
domains = [
t ∈ IntervalDomain(0.0,1.0),
x ∈ IntervalDomain(0.0,1.0),
y ∈ IntervalDomain(0.0,1.0)
]
# Discretization
dx = 0.04
nd = round(Int, 1 / dx) + 1
discretization = MOLFiniteDifference([x=>dx,y=>dx],t)Solve steady-state problem to find a linearization point
We discretize the PDE using MethodOfLines.jl, which uses a finite-difference approximation.
We create the matrix $M$ that contains the steady-state solution, we will later use this as the reference in the control problem. The root solver only solves for the interior of the domain, so we have to manually expand $M$ to contain zeros on the boundary.
eqss = Dt(u(t,x,y)) ~ Dxx(u(t,x,y)) + Dyy(u(t,x,y)) + sin(pi*x)*sin(pi*y)
@named pde_systemss = PDESystem([eqss],bcs,domains,[t,x,y],[u(t,x,y)])
ss_sys, tspan = SciMLBase.symbolic_discretize(pde_systemss, discretization)
ss_odeprob = discretize(pde_systemss,discretization)
probss = SteadyStateProblem(ss_odeprob)
ss_sol = solve(probss,SSRootfind());
M_ss = zeros(nd,nd)
M_ss[2:end-1, 2:end-1] .= reshape(ss_sol.u, nd-2, nd-2)2D PDE with input for linearization
We now add the control input variable $a$ to the equation, we then discretize the problem and linearize the spatially discretized system. The operating point in which to linearize is taken to be the steady-state solution from above. The function named_ss performs both linearization using ModelingToolkit.linearize as well as creating a NamedStateSpace using the returned Jacobians.
# The actuation input `a` acts through the actuator influence function
eqi = Dt(u(t,x,y)) ~ Dxx(u(t,x,y)) + Dyy(u(t,x,y)) + sin(pi*x)*sin(pi*y) + Ainfluence(x,y)*a
@named pde_systemi = PDESystem([eqi],bcs,domains,[t,x,y],[u(t,x,y)])
odesys, _ = SciMLBase.symbolic_discretize(pde_systemi, discretization)
s = states(odesys)
inputs = [a]
outputs = s[(end÷2-3:end÷2+3) .- 13] # Extract a number of state variables in the middle of the domain that will serve as our "controlled outputs"
op = Dict([a=>0; states(ss_sys) .=> vec(M_ss)])
lsys = named_ss(odesys, inputs, outputs; op)
w = exp10.(-2:0.01:2)
figb = bodeplot(lsys, w, plotphase=false, layout=1)
The linear system has a large number of state variables:
lsys.nx576In a practical scenario where we deploy the controller using an observer, or if we implement an MPC controller etc. ee could perform model-order reduction to reduce the computational complexity:
rsys, Gram, Tr = baltrunc(lsys) # Perform model reduction(pde_systemi: NamedStateSpace{Continuous, Float64}
A =
-49.63972105560234 -62.32910622728326 -20.03118814400609 0.24818889446971568
-69.83239844780859 -193.65861266941187 -136.9670298449962 -24.977369736857668
-42.834413465290986 -189.95643663934322 -407.2914868284225 -226.65417136965416
-17.65949436877476 -84.80970889522511 -306.7568982570304 -603.0873246298655
B =
0.9832119862077783
0.7950394354701368
0.4288086357137263
0.17488405161879234
C =
0.23502314511182476 -0.030658115061445248 -0.15784357978673003 -0.03308442829739643
0.3145430493835905 0.12354560083443236 -0.0879112051567215 -0.08454862778100063
0.39508067277710646 0.3129596477791336 0.08988149502227995 -0.0212022447550593
0.4480054660655993 0.44985179264197506 0.25233719910437546 0.08453946069804394
0.44800546606560065 0.44985179264197334 0.2523371991043762 0.08453946069804477
0.395080672777107 0.3129596477791305 0.08988149502228154 -0.021202244755058844
0.3145430493835915 0.12354560083442875 -0.08791120515671964 -0.0845486277809988
D =
0.0
0.0
0.0
0.0
0.0
0.0
0.0
Continuous-time state-space model
With state names: x1 x2 x3 x4
input names: a(t)
output names: (u(t))[10, 13] (u(t))[11, 13] (u(t))[12, 13] (u(t))[13, 13] (u(t))[14, 13] (u(t))[15, 13] (u(t))[16, 13]
, [0.009737220408025844, 0.0016319638337792123, 0.00022573126619281316, 2.5356553074113545e-5], [0.0001333843961195366 0.00026835235632655395 … 0.00019314900097546582 9.598652461152032e-5; -0.00035687453211717733 -0.0007147975855029515 … -0.000529894364389131 -0.00026423187770267917; 0.000671544031681225 0.0013356135264607598 … 0.0010430270808151967 0.0005227489093966413; -0.0013450044064512168 -0.002643949098186396 … -0.0022724697824616433 -0.0011474899472364714])This resulted in a model of order 3-4 only, but if you plot in in a Bode plot together with the full-order model you'll see that their frequency responses are identical.
Design an LQR controller
We penalize the output only, i.e., the few grid cells in the center that were selected as output when we performed the linearization. This is realized by choosing the state-penalty matrix $Q = C^T C$, since
\[y^T Q_y y = (Cx)^T Q_y (Cx) = x^T C^T Q_y C x\]
(we chose $Q_y = I$)
C = lsys.C
Q = C'*C
R = 0.00000001
L = lqr(lsys, Q, R)1×576 Matrix{Float64}:
0.0222639 0.044621 0.0669597 … 0.00739653 0.00480403 0.00236331How does the LQR controller behave?
inp(x, t) = -L*x
res = lsim(lsys, inp, 0:0.01:0.6, x0=ones(lsys.nx)) # Simulate closed loop
figs = plot(res.t, res.y', plot_title="lsim", layout=1, lab=permutedims(output_names(lsys)))
Since the state-feedback matrix corresponds to states across a spatial domain, we ca reshape the matrix $L$, which is currently $L \in \mathbb{R}^{1 \times n_x n_y}$ into $L_{mat} \in \mathbb{R}^{n_x \times n_y}$ and visualize it:
Lmat = zeros(nd, nd)
Lmat[2:end-1, 2:end-1] .= reshape(L, nd-2, nd-2)
heatmap(Lmat, title="State feedback array \$L(x, y)\$")
Unsurprisingly, it looks like to controller only cares about the few state variables in the center which we selected to penalize when we chose the outputs for linearization.
Closed-loop simulation with disturbance
The disturbance is sinusoidal, $d = 2\sin(20t)$ and acts through the disturbance-influence function, which has support slightly below the center point of the domain where the actuator-influence function has support.
To simulate the closed-loop system, we extend the discretized LQR controller feedback matrix $L$ to a continuous spatial domain $L(x, y)$ using an interpolation. The full controller will thus be
\[a(x, t) = L(x, t) \big(u(x, t) - M(x, t)\big)\]
where $M$ is the reference solution obtained from the steady-state problem above, also made continuous through interpolation.
We simulate twice, once with the controller active (controlled = 1) and once with the controller turned off (controlled = 0).
nodes = (0:dx:1, 0:dx:1) # For interpolation
# Create continuous state-feedback function using a 2D linear interpolator
Lfun = interpolate(nodes, Lmat, Gridded(Linear()))
Lint(x, y) = Lfun(x, y)
@register_symbolic Lint(x, y)
# Create a 2D interpoaltion also for the steady-state solution
Mfun = interpolate(nodes, M_ss, Gridded(Linear()))
Mint(x, y) = Mfun(x, y)
@register_symbolic Mint(x, y)
@parameters controlled=1
eqcl = Dt(u(t,x,y)) ~ Dxx(u(t,x,y)) + Dyy(u(t,x,y)) + sin(pi*x)*sin(pi*y) - controlled*Ainfluence(x,y)*Lint(x, y)*(u(t,x,y) - Mint(x, y)) + Dinfluence(x,y)*2sin(20t)
@named pde_systemcl = PDESystem([eqcl],bcs,domains,[t,x,y],[u(t,x,y)], [controlled=>1])
probcl = discretize(pde_systemcl,discretization)
sol_control = solve(probcl,Tsit5())
no_controlprob = remake(probcl, p = [0]) # Turn off the controller
sol_nocontrol = solve(no_controlprob,Tsit5())┌ Warning: : no method matching get_unit for arguments (Pair{Symbolics.Num, Int64},).
└ @ ModelingToolkit ~/.julia/packages/ModelingToolkit/Nsxrf/src/systems/validation.jl:154
┌ Warning: : no method matching get_unit for arguments (Pair{Symbolics.Num, Int64},).
└ @ ModelingToolkit ~/.julia/packages/ModelingToolkit/Nsxrf/src/systems/validation.jl:154
┌ Warning: : no method matching get_unit for arguments (Pair{Symbolics.Num, Int64},).
└ @ ModelingToolkit ~/.julia/packages/ModelingToolkit/Nsxrf/src/systems/validation.jl:154Visualization
We now have a look at the solution to the PDE, with and without the controller active. The controller acts in the center of the domain, while the disturbance acts slightly below the center. It's somewhat hard to see the difference in this kind of plot, but the controller reduces the variation in the center of the domain. Below, we show a time-series plot of the center to make it easier to spot the difference.
With control, notice how the center stays relatively constant:
function showsol(sol)
xg = 0:dx:1
yg = 0:dx:1
tvec = 0:0.012:1
@gif for i in tvec
M = sol(i, :, :)[]
heatmap(xg,yg,M, clims = (0, 0.06), levels=100)
end
end
showsol(sol_control)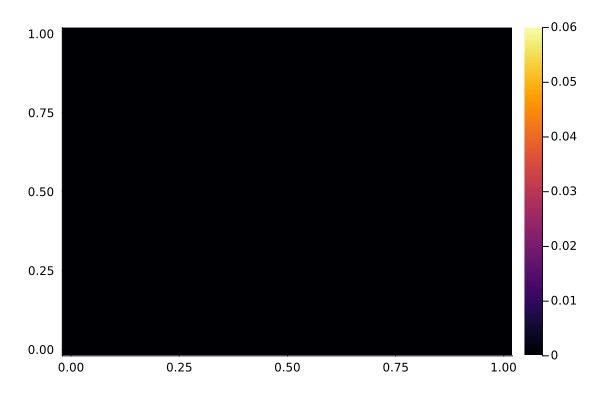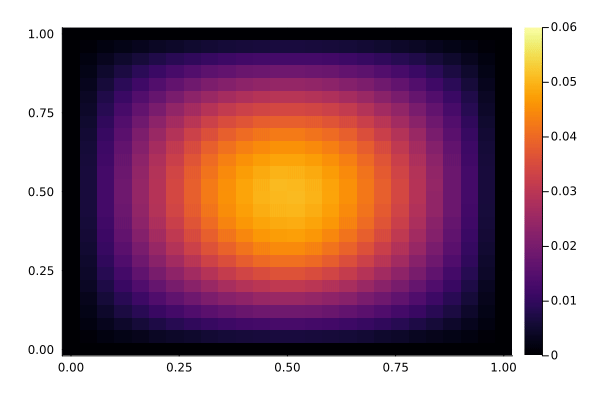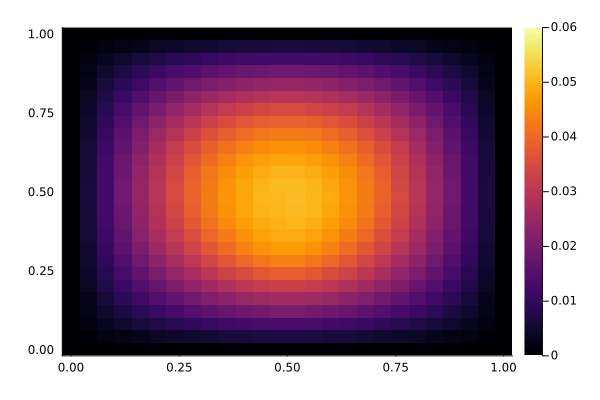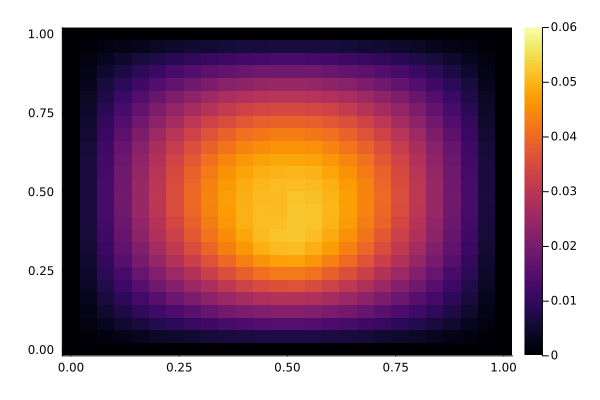
Without control, notice how the center fluctuates due to the disturbance:
showsol(sol_nocontrol)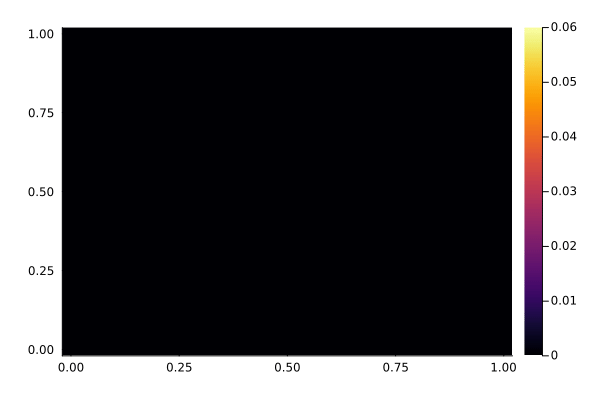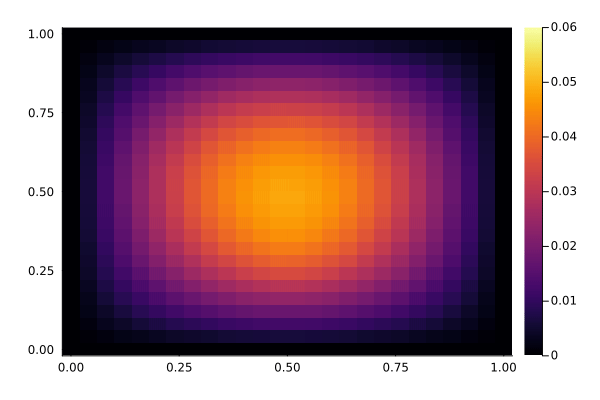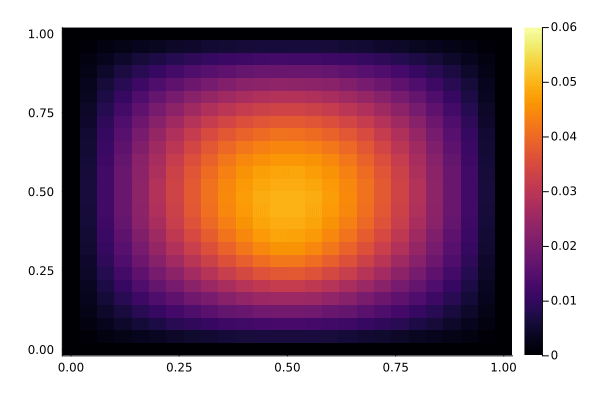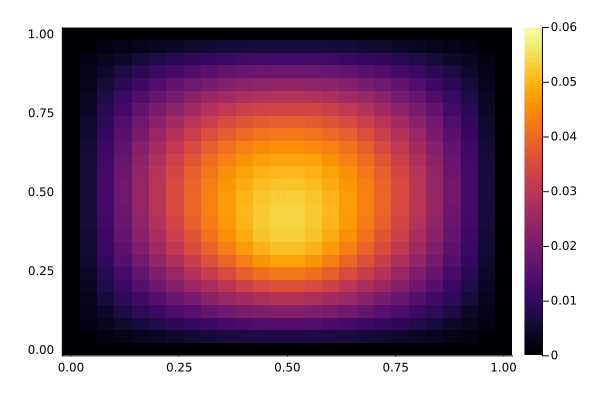
Below, we show the solutiuon for a number of cells in the center of the domain:
yinds = (-1:1) .+ nd ÷ 2
xind = nd ÷ 2
ref = M_ss[xind, yinds]
plot(sol_control.t, sol_control[u(t,x,y)][:, xind, yinds], c=1, lab="Controlled")
plot!(sol_nocontrol.t, sol_nocontrol[u(t,x,y)][:, xind, yinds], c=2, lab="Uncontrolled")
hline!(ref', l=(:black, :dash, 0.2), lab="References")
MPC
Below, we show how to solve the same control problem as before, but this time using a linear MPC controller. To make it a bit more interesting, we include rather restrictive bounds on the control input (without these bounds, the MPC controller had been equivalent to the LQR controller).
We start by defining a symbolic equation that has a symbolic variable input to represent the control signal computed by the MPC controller.
using JuliaSimControl: StateFeedback
using JuliaSimControl.MPC
using LinearAlgebra, Statistics
@variables input(t) [input=true]
eqmpc = Dt(u(t,x,y)) ~ Dxx(u(t,x,y)) + Dyy(u(t,x,y)) + sin(pi*x)*sin(pi*y) + Ainfluence(x,y)*input + Dinfluence(x,y)*2sin(20t)
@named pde_systemmpc = PDESystem([eqmpc],bcs,domains,[t,x,y],[u(t,x,y)])\[ \begin{align} \frac{\mathrm{d}}{\mathrm{d}t} u\left( t, x, y \right) =& \frac{\mathrm{d}}{\mathrm{d}x} \frac{\mathrm{d}}{\mathrm{d}x} u\left( t, x, y \right) + \frac{\mathrm{d}}{\mathrm{d}y} \frac{\mathrm{d}}{\mathrm{d}y} u\left( t, x, y \right) + \mathrm{input}\left( t \right) e^{100 \left( - \left( -0.5 + x \right)^{2} - \left( -0.5 + y \right)^{2} \right)} + 2 e^{100 \left( - \left( -0.3 + x \right)^{2} - \left( -0.5 + y \right)^{2} \right)} \sin\left( 20 t \right) + \sin\left( \pi y \right) \sin\left( \pi x \right) \end{align} \]
We then discretize this version of the PDE system and call ModelingToolkit.generate_control_function to generate a dynamics function that takes not only the state as argument, but also the control signal.
"""
A helper function that discretizes the PDE system (in space) and generates a control function with signature f_oop = ẋ <- f(x, u, p, t) for the discretized system.
"""
function pde_control_function(pde_systemmpc, discretization, inputs)
discsys, _ = SciMLBase.symbolic_discretize(pde_systemmpc, discretization)
(f_oop, f_ip), dvs, p, io_sys = ModelingToolkit.generate_control_function(discsys, inputs)
end
(f_oop, f_ip), dvs, p, io_sys = pde_control_function(pde_systemmpc, discretization, [input]);We are now ready to setup the MPC controller, we will use the problem type LQMPCProblem which takes a LinearMPCModel. To make the MPC controller performant, we will use the reduced-order model rsys that we computed above (select between full and reduced order using the use_reduced variable). We will also use the steady-state solution M_ss as the reference for the MPC controller. We use a prediction horizon of N = 5 steps and control input bounds of $u \in [-0.7, 0.7]$.
Ts = 0.01 # Sample time of the MPC controller
use_reduced = true # Indicate whether or not to use the reduced-order linear model for MPC
if use_reduced
# Relax, we already have the correct Tr matrix
else # Use full-order model
Tr = I(lsys.nx) # The reduction matrix is the identity matrix
end
dsys = c2d(use_reduced ? rsys : lsys, Ts) # Discretize the linear system
(; nx,ny,nu) = dsys
N = 5 # MPC prediction horizon
x0 = zeros(lsys.nx) # Initial condition of full-order linear system
op = OperatingPoint(Tr*ss_sol.u, 0, dsys.C*Tr*ss_sol.u) # Set the operating point to the steady-state solution (possibly reduced to the statespace of the reduced-order model)
# Control limits
umin = -0.7 * ones(nu)
umax = 0.7 * ones(nu)
constraints = MPCConstraints(; umin, umax)
solver = OSQPSolver(
verbose = false,
eps_rel = 1e-4,
max_iter = 100,
check_termination = 5,
polish = false,
)
discrete_dynamics = MPC.rk4(f_oop, Ts, supersample=20)
observer = StateFeedback(discrete_dynamics, Tr*x0, nu, ny) # We assume that we have access to the true state, see the MPC documentation for help on how to implement an observer
predmodel = LinearMPCModel(dsys, observer; constraints, op, x0 = Tr*x0)
prob = LQMPCProblem(predmodel; Q1=dsys.C'dsys.C, Q2=[R;;], N, solver, r=op.x)LQMPCProblem{LinearMPCModel{Discrete{Float64}, NamedStateSpace{Discrete{Float64}, StateSpace{Discrete{Float64}, Float64}}, StateFeedback{SeeToDee.Rk4{RuntimeGeneratedFunctions.RuntimeGeneratedFunction{(:ˍ₋arg1, :ˍ₋arg2, :ˍ₋arg3, :t), Symbolics.var"#_RGF_ModTag", Symbolics.var"#_RGF_ModTag", (0x074e574c, 0x43d21b34, 0x54378c1d, 0xaedefb7e, 0x69220e3d), Expr}, Float64}, Vector{Float64}}, OperatingPoint{Vector{Float64}, Int64, Vector{Float64}}, LinearAlgebra.Diagonal{Bool, Vector{Bool}}, SparseArrays.SparseMatrixCSC{Float64, Int64}, SparseArrays.SparseMatrixCSC{Float64, Int64}, MPCConstraints{Vector{Float64}, Nothing}}, Vector{Float64}, Matrix{Float64}, Matrix{Float64}, SparseArrays.SparseMatrixCSC{Float64, Int64}, LinearAlgebra.Diagonal{Bool, Vector{Bool}}, Vector{Float64}, Vector{Float64}, SparseArrays.SparseMatrixCSC{Float64, Int64}, JuliaSimControl.MPC.OSQPSolverWorkspace, Matrix{Float64}, SciMLBase.NullParameters, Nothing}(LinearMPCModel{Discrete{Float64}, NamedStateSpace{Discrete{Float64}, StateSpace{Discrete{Float64}, Float64}}, StateFeedback{SeeToDee.Rk4{RuntimeGeneratedFunctions.RuntimeGeneratedFunction{(:ˍ₋arg1, :ˍ₋arg2, :ˍ₋arg3, :t), Symbolics.var"#_RGF_ModTag", Symbolics.var"#_RGF_ModTag", (0x074e574c, 0x43d21b34, 0x54378c1d, 0xaedefb7e, 0x69220e3d), Expr}, Float64}, Vector{Float64}}, OperatingPoint{Vector{Float64}, Int64, Vector{Float64}}, LinearAlgebra.Diagonal{Bool, Vector{Bool}}, SparseArrays.SparseMatrixCSC{Float64, Int64}, SparseArrays.SparseMatrixCSC{Float64, Int64}, MPCConstraints{Vector{Float64}, Nothing}}
A =
0.6959900716796642 -0.2232738473752085 0.02583012431865295 0.0027808261893429967
-0.2363802038727263 0.3239108624304645 -0.15484478884371236 0.047133213525881706
0.014939969697005407 -0.19006349127366237 0.1539697540560584 -0.06412126773591631
0.008544178358300784 0.059029558773849085 -0.07542531223463055 0.037589616179337135
B =
0.006910803449876607
0.0020916513754191297
-0.0004280963610391468
-3.778961892544804e-5
C =
0.23502314511182476 -0.030658115061445248 -0.15784357978673003 -0.03308442829739643
0.3145430493835905 0.12354560083443236 -0.0879112051567215 -0.08454862778100063
0.39508067277710646 0.3129596477791336 0.08988149502227995 -0.0212022447550593
0.4480054660655993 0.44985179264197506 0.25233719910437546 0.08453946069804394
0.44800546606560065 0.44985179264197334 0.2523371991043762 0.08453946069804477
0.395080672777107 0.3129596477791305 0.08988149502228154 -0.021202244755058844
0.3145430493835915 0.12354560083442875 -0.08791120515671964 -0.0845486277809988
D =
0.0
0.0
0.0
0.0
0.0
0.0
0.0
Sample Time: 0.01 (seconds)
Discrete-time state-space model, [0.2040978061574845, -0.1102750856475372, 0.03813810702664562, -0.012056294815718353], [0.9667058098226436 0.7208761938631966 0.2047171603809684 -0.0019688860620520306; 0.7208761938631966 0.632087703952674 0.2664043460912661 0.04291264595828473; 0.2047171603809684 0.2664043460912661 0.1838768460626672 0.05894123066265969; -0.0019688860620520306 0.04291264595828473 0.05894123066265969 0.03058443151060487], [1.0e-8;;], nothing, sparse([1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4], [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4], [0.9783774467607901, 0.7150268993721816, 0.2053948315083494, -0.001701805495570197, 0.7150268993721816, 0.6354336708320859, 0.2657377279043815, 0.0429112377054129, 0.2053948315083494, 0.2657377279043815, 0.18417873232933724, 0.05884926783269989, -0.001701805495570197, 0.0429112377054129, 0.05884926783269989, 0.030634812104043254], 4, 4), [0.9667058098226436 0.7208761938631966 0.2047171603809684 -0.0019688860620520306; 0.7208761938631966 0.632087703952674 0.2664043460912661 0.04291264595828473; 0.2047171603809684 0.2664043460912661 0.1838768460626672 0.05894123066265969; -0.0019688860620520306 0.04291264595828473 0.05894123066265969 0.03058443151060487], 0.0, 0.0, Bool[1 0 0 0; 0 1 0 0; 0 0 1 0; 0 0 0 1], [0.2040978061574845, -0.1102750856475372, 0.03813810702664562, -0.012056294815718353], [-0.7], [0.7], 5, sparse([1, 2, 3, 4, 1, 2, 3, 4, 1, 2 … 28, 29, 26, 27, 28, 29, 26, 27, 28, 29], [1, 1, 1, 1, 2, 2, 2, 2, 3, 3 … 27, 27, 28, 28, 28, 28, 29, 29, 29, 29], [0.9667058098226436, 0.7208761938631966, 0.2047171603809684, -0.0019688860620520306, 0.7208761938631966, 0.632087703952674, 0.2664043460912661, 0.04291264595828473, 0.2047171603809684, 0.2664043460912661 … 0.2657377279043815, 0.0429112377054129, 0.2053948315083494, 0.2657377279043815, 0.18417873232933724, 0.05884926783269989, -0.001701805495570197, 0.0429112377054129, 0.05884926783269989, 0.030634812104043254], 29, 29), [-0.0, -0.0, -0.0, -0.0, 0.0, -0.0, -0.0, -0.0, -0.0, 0.0 … 0.0, -0.0, -0.0, -0.0, -0.0, 0.0, 0.0, 0.0, 0.0, 0.0], sparse([1, 5, 6, 7, 8, 2, 5, 6, 7, 8 … 24, 21, 22, 23, 24, 29, 21, 22, 23, 24], [1, 1, 1, 1, 1, 2, 2, 2, 2, 2 … 24, 25, 25, 25, 25, 25, 26, 27, 28, 29], [-1.0, 0.6959900716796642, -0.2363802038727263, 0.014939969697005407, 0.008544178358300784, -1.0, -0.2232738473752085, 0.3239108624304645, -0.19006349127366237, 0.059029558773849085 … 0.037589616179337135, 0.006910803449876607, 0.0020916513754191297, -0.0004280963610391468, -3.778961892544804e-5, 1.0, -1.0, -1.0, -1.0, -1.0], 29, 29), [-0.0, -0.0, -0.0, -0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, -0.7, -0.7, -0.7, -0.7, -0.7], [-0.0, -0.0, -0.0, -0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 … 0.0, 0.0, 0.0, 0.0, 0.0, 0.7, 0.7, 0.7, 0.7, 0.7], JuliaSimControl.MPC.OSQPSolverWorkspace(OSQP.Model(Ptr{OSQP.Workspace} @0x0000000034381140, [6.9027400509329e-310, 6.95306411365317e-310, 6.90245034601944e-310, 6.9024520429642e-310, 6.90248216272135e-310, 6.9025713578398e-310, 6.902571357839e-310, 6.95293140867686e-310, 7.4e-323, 5.0e-323 … 6.90250243224115e-310, 6.90244371366165e-310, 6.90243139623436e-310, 6.90243139625017e-310, 6.90244371367746e-310, 6.90244371368537e-310, 6.90244371369327e-310, 6.9027400509329e-310, 6.90249198634637e-310, 0.0], [6.9027400509329e-310, 6.95306411365317e-310, 6.90245034601944e-310, 6.9024520429642e-310, 6.90248216272135e-310, 6.9025713578398e-310, 6.902571357839e-310, 6.95293140867686e-310, 7.4e-323, 5.0e-323 … 6.90250243224115e-310, 6.90244371366165e-310, 6.90243139623436e-310, 6.90243139625017e-310, 6.90244371367746e-310, 6.90244371368537e-310, 6.90244371369327e-310, 6.9027400509329e-310, 6.90249198634637e-310, 0.0], false), OSQPSolver(false, 0.0001, 1.0e-5, 100, 5, 2, 1, false, 1.0e10)), [0.0 0.0 … 0.0 0.0; 0.0 0.0 … 0.0 0.0; 0.0 0.0 … 0.0 0.0; 0.0 0.0 … 0.0 0.0], [0.0 0.0 … 0.0 0.0], SciMLBase.NullParameters(), nothing)We discretize the PDE system in time using the RK4 integrator, and implement a little helper function mpc_sim to perform the simulation for us. In the main simulation loop, we call the low-level function MPC.optimize!, which requires us to handle the operating point manually, we thus adjust the state using the operating point op before calling MPC.optimize!. The matrix Tr is used to map the state from the full-order model to the reduced-order model.
function mpc_sim(f_oop; T = 100, Ts, p, op)
discrete_dynamics = MPC.rk4(f_oop, Ts, supersample=20)
X = [x0]
U = []
Ymiddle = [] # Keep track of the same outputs as we plotted above
D = zeros(nd, nd)
for i = 1:T
t = (i-1)*Ts
x = X[end]
Δx = Tr*x - op.x # Since we call the low-level function optimize! directly, we manually adjust for the operating point
co = MPC.optimize!(prob, Δx, p, t; verbose=false)
Δu = co.u[1]
u = Δu + op.u
xp = discrete_dynamics(x, u, p, t)
D[2:end-1, 2:end-1] .= reshape(x, nd-2, nd-2)
push!(X, xp)
push!(U, u)
push!(Ymiddle, D[xind, yinds])
end
range(0, step=Ts, length=T), X, U, Ymiddle
end
tmpc, X, U, Ymiddle = mpc_sim(f_oop; T = 100, Ts, p, op)
figsol = plot(sol_control.t, sol_control[u(t,x,y)][:, xind, yinds], c=1, lab="Controlled")
plot!(sol_nocontrol.t, sol_nocontrol[u(t,x,y)][:, xind, yinds], c=2, lab="Uncontrolled")
plot!(figsol, tmpc, reduce(hcat, Ymiddle)', lab="MPC", c=3)
hline!(ref', l=(:black, :dash, 0.2), lab="References")
figu = plot(tmpc, reduce(hcat, U)', lab="u")
plot(figsol, figu)
We see that the MPC controller behaves similar to the LQR controller, but respects the input constraints that we imposed. In this case, the reduced order model has
rsys.nx4state variables, while the full-order model has
lsys.nx576Solving the MPC problem with the full-order model is thus significantly more expensive than solving it with the reduced-order model, but the results are almost identical.