Processing and hosting large datasets on JuliaHub
Aggregating and charting foreign exchange data
In this tutorial we will show how to access large amounts of private data on JuliaHub. As an example of a data-heavy task, we'll be processing currency exchange data in the format of the TrueFX platform.
Structure of the data
The currency exchange data comes in tabular zipped CSV format; decoded, it looks something like
│ pair │ timestamp │ bid │ ask │
│ String │ DateTime │ Float64 │ Float64 │
├─────────┼─────────────────────────┼─────────┼─────────┤
│ EUU/UDD │ 2020-01-01T00:00:00 │ 1.29999 │ 1.29999 │
│ EUU/UDD │ 2020-01-01T00:00:59.114 │ 1.30001 │ 1.30001 │
│ EUU/UDD │ 2020-01-01T00:02:10.085 │ 1.29987 │ 1.29987 │
│ EUU/UDD │ 2020-01-01T00:02:36.993 │ 1.30001 │ 1.30002 │
│ EUU/UDD │ 2020-01-01T00:02:58.374 │ 1.30011 │ 1.30012 │
⋮The columns describe a pair of currencies:
pairis a currency pairB/Q("base/quote" currencies)timestampis the date and timebidis how much ofQwill be obtained when buying one unit ofBaskis how much ofQmust be paid to buy one unit ofB
The source data is one .csv file per currency pair per month, compressed in .zip format. We're going to leave it in that format to save on bandwidth and download time when moving the data around. In total, the full year of TrueFx data for 2020 has 240 files of 4.4GB in size.
Generating example data
To ensure people can follow this tutorial without making a TrueFX account, we provide generate_data.jl which generates example data in this format. We're also going to use the generated data for the graphs in this tutorial so you can follow along. In the generator, we've paid attention to the format of the data, but not tried to reproduce any statistical properties! We've also reduced the time series frequency by a factor of 100 to reduce the total size you'll need to upload.
Run the generator now:
- Download generate_data.jl along with the Project.toml and Manifest.toml files to a new directory.
- Activate the environment (for example, right click the Project.toml and select "Julia: Activate This Environment).
- Run the file (for example, right click
generate_data.jland select "Julia: Execute File in REPL")
The generator will create
- A
currency_datadirectory with a zip file per month for the fictional currency pairs"EUU/UDD"and"UDD/JPP". - A
Data.tomlfile in the current directory, for use with DataSets.jl on your local machine.
Loading the dataset locally using DataSets.jl and Data.toml, you should see something like
julia> using DataSets
julia> DataSets.load_project!(path"Data.toml")
julia> open(BlobTree, dataset("username/currency_data"))
📂 Tree @ .../currency_data
📄 EUUUDD-2020-01.zip
📄 EUUUDD-2020-02.zip
📄 EUUUDD-2020-03.zip
📄 EUUUDD-2020-04.zip
⋮
📄 UDDJPP-2020-09.zip
📄 UDDJPP-2020-10.zip
📄 UDDJPP-2020-11.zip
📄 UDDJPP-2020-12.zipIn this tutorial we're focussing mostly on using DataSets with JuliaHub. For more detail on how to work with DataSets.jl on your own computer, see the DataSets.jl tutorial documentation.
Loading and plotting a month of data locally
Let's load and plot a single one of these CSV files on your local machine. For example, our simulated bid price over the month of January 2020. Note the gaps - we're simulating the fact that currencies aren't traded on the weekend.
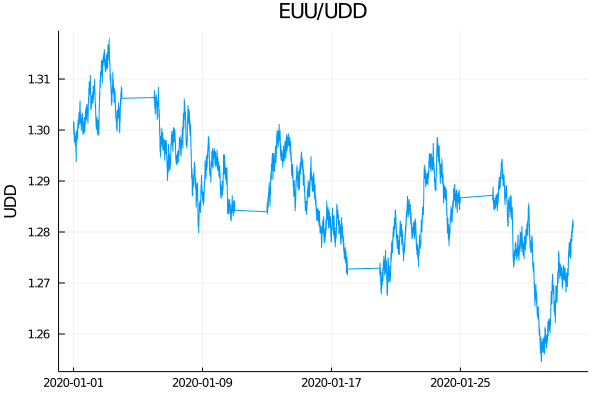
The code to produce this plot uses the ZipFile and CSV packages to decode the files via load_truefx_csv():
using CSV
using ZipFile
using Dates
using DataFrames
using Plots
using DataSets
using Underscores
function load_truefx_csv(csv_blob)
@info "Loading $(basename(csv_blob))"
open(IO, csv_blob) do io
zipped_content = only(ZipFile.Reader(io).files)
buf = read(zipped_content)
CSV.read(buf, DataFrame,
header=["pair", "timestamp", "bid", "ask"],
dateformat=dateformat"yyyymmdd H:M:S.s",
types=Dict(:timestamp=>DateTime))
end
endWe use the DataSets.jl package for organizing data access; this will become important when accessing data within JuliaHub. Here's the code to load and plot the month of data:
# Initialize DataSets
DataSets.load_project!(path"Data.toml")
# Open the dataset
data = open(BlobTree, dataset("username/currency_data")) do tree
load_truefx_csv(tree["EUUUDD-2020-01.zip"])
end
# Plot
plot(data.timestamp, data.bid, label=nothing,
title=data.pair[1], ylabel=split(data.pair[1], '/')[2])
savefig("EUUUDD-2020-01.png")See the complete plotting code here.
Uploading the data
Now let's upload the data to JuliaHub using the VSCode JuliaHub integration, which currently the best option for larger files and folders. In VSCode, select "JuliaHub: Upload folder", select the currency_data folder and select currency_data as the dataset name. You can add tags and a description to help you organize your data, but you can leave these blank for now.
You can see the upload progress in the JuliaHub output console:
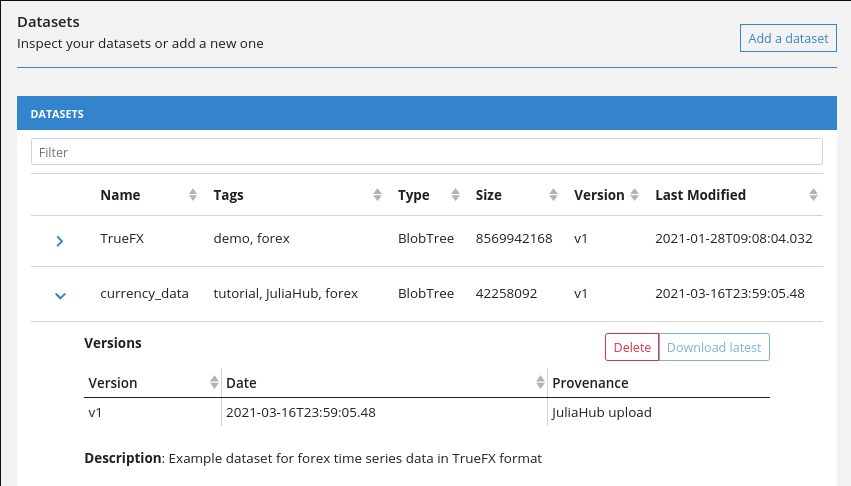
Once the upload is done, you'll be able to see the currency_data dataset in the Web interface at juliahub.com. You'll also note in this example screenshot that I've got both the demo currency_data and a real TrueFX dataset uploaded here:
All the datasets within the web UI will automatically be exposed to your JuliaHub compute jobs to be loaded on demand.
The data access and processing code
In this section, we'll refer to the code within process_data.jl. This code computes a simple "OHLC" summary of the time series, partitioning the high frequency price data into days and computing the Open, Low, High and Close prices for that day (see compute_ohlc() in process_data.jl).
Here we'll focus on the data access rather than the processing code. Data is accessed with the dataset() and open() functions which give you uniform access to the data regardless of whether you're running locally or on JuliaHub. See the DataSets.jl documentation for more about these.
To compute the OHLC across the entire dataset with a single process (locally or in JuliaHub), you can iterate over the currency_data data tree, load and process each file using
ohlc_per_file = open(BlobTree, dataset("username/currency_data")) do tree
map(tree) do blob
full_data = load_truefx_csv(blob)
ohlc = compute_ohlc(full_data, :bid, t->floor.(t, Dates.Day(1)))
end
end
ohlc_data = reduce(vcat, ohlc_per_file)As a final step, we need to save this data and tell JuliaHub that it should make the results available to us for later download. This is done by saving a results file and setting the environment variable ENV["RESULTS_FILE"]:
CSV.write("ohlc_data.csv", ohlc_data)
ENV["RESULTS_FILE"] = "ohlc_data.csv"Running the code
Try running process_data.jl now
- Download process_data.jl and the
Data.tomlfile is. It's important not to place your scripts in the same directory as your data to avoid the data being redundantly uploaded with the code. (This does work for uploading small amounts of data with the code, but not for large datasets.)- Launch process_data.jl as a single node non-distributed job from the
You can inspect your job logs while the code is running to check which datasets JuliaHub has provided to your jobs. Look for the line "Initialized JuliaHub hosted DataSets":
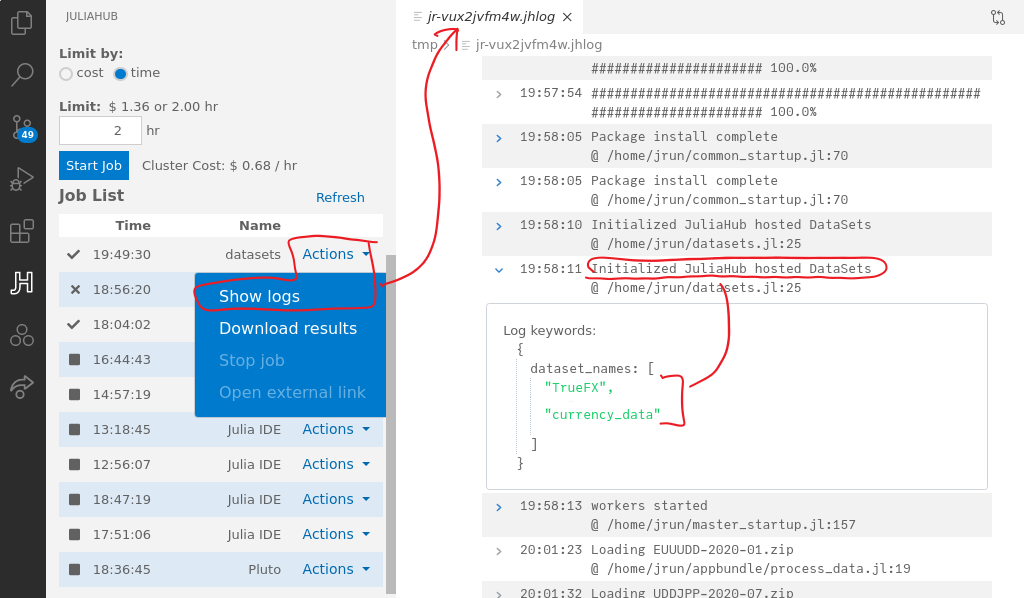
Downloading and Plotting
After the job has completed, JuliaHub will make the file named in ENV["RESULTS_FILE"] available for download:
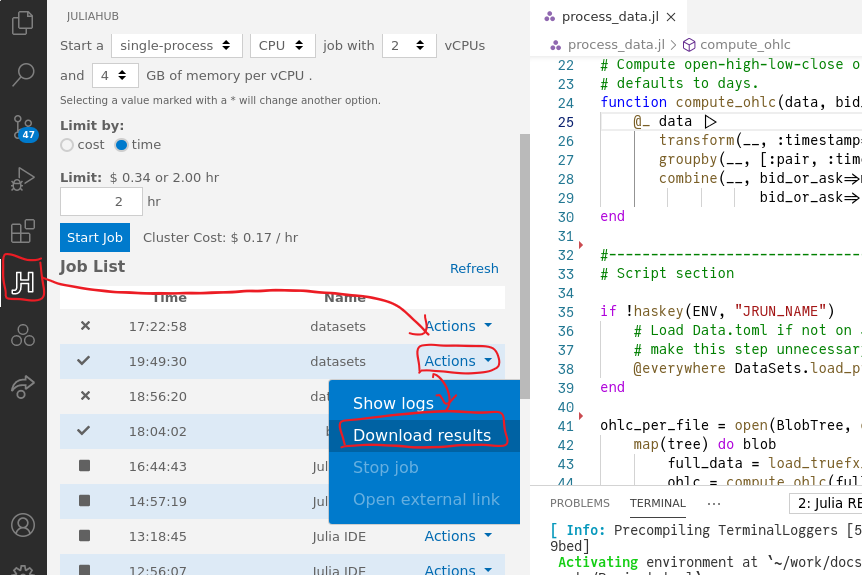
We can plot the OHLC data using a candlestick chart which shows bars with top and bottom being the open and close prices over the interval, and the high and low being a vertical line. When the close is higher than open, the bar will be green; otherwise red. Here's the first quarter year of our fictional EUU/UDD currency pair:

See the code in plotting.jl to make your own version of this.
Next Steps
- The single-process code above is fast enough for the small example dataset, but for a more realistic size you'll want to distribute the code across multiple computers. There's a version of this code which distributes the data decoding and processing across multiple nodes of a cluster using Distributed.jl in process_data_distributed.jl.