Reference Documentation
Parallelism and compute structure
JuliaHub supports fully heterogeneous parallel compute. It uses the Distributed standard library to parallelize across workers on potentially many machines. Each worker can support multiple threads with the builtin Threads module. Each machine can optionally have a computational GPU attached to it for further acceleration with the CUDA package.
All of these modes of operation are fully supported and JuliaHub ensures that all machines in the cluster have the appropriate files and dependencies in place. This means, for example, that you do not need to addprocs or set the number threads yourself; your code should use scale-invariant constructs like pmap, @distributed and @threads or other higher-level abstractions like those for DifferentialEquations.jl.
JuliaHub also scales seamlessly from simple single-file scripts to whole applications with many thousands of lines of code, dependencies (both private and public), binary artifacts, and data. Your IDE will automatically detect all such dependencies, bundle them together, and ensure their availability on every node.
Project, Manifest and Artifacts
When running from VS Code or Juno, these are pre-populated based upon your active project.
When running ad-hoc code, you may choose them manually.
Outputs
Set ENV["RESULTS"] to contain a simple JSON string to display certain values in the Output table. This is helpful for a handful of summary values to compare jobs at a glance on JuliaHub through the Details button. The contents of ENV["RESULTS"] are restricted to 1000 characters. If a longer value is set, it will be truncated.
You can further set the ENV["RESULTS_FILE"] to a local file on the filesystem that will be available for download after job completion. While there is only one results file per job, note that you can zip or tar multiple files together. The overall size of the results (the single file or the tar bundle) is limited to 5GiB. Upload of result exceeding that size is would fail, and they will not be available for download later.
Cluster design
Choose the number of cores and machines as appropriate:
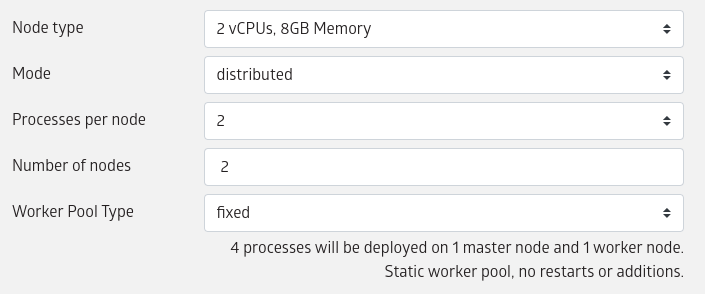
Select the node type that you wish to use. Node types determine the vCPU, memory, and type of GPU available on each node.
It is possible to either start a job with single Julia process or with multiple Julia processes.
- To start a job with single Julia process, select
single-processfor "Mode". - To start a job with multiple Julia processes, select
distributedfor "Mode".
The vCPU and memory selections will determine the node type/size on which the job will be run.
The actual number of Julia processes that will be started depends on the selection for processes per node and number of nodes, such that total number of Julia processes = number of nodes * processes per node.
Note that one Julia process will always be designated to be the master and the remaining would be worker processes.

The worker pool type of a distributed job can be one of fixed or elastic.
A job with fixed worker pool would wait for all (or a configured minimum) number of workers to join before the job code is executed. Once the job code starts executing, no more (delayed) workers are allowed to join. Also if any worker fails during execution it would not be restarted.
A job with an elastic worker pool would not wait for workers before starting to execute the job code. But it would allow workers to join any time while the job code is running. And if any worker fails during execution they would be restarted.
Elastic worker pools
An elastic worker pool has the advantage of quick start times and is resilient to failures. However they may not be suitable for all types of programs.
Programs that do not depend on workers being initialized in a specific way should already be compatible to the elastic mode. The only change that they may need is where the code needs a certain minimum number of workers to work, they may need to add a check. E.g.:
using Distributed
@assert :ok === timedwait(120.0; pollint=5.0) do
nworkers() >= min_workers_required
endPrograms that require specific initialization steps to be done on the worker, typically done via one or more @everywhere macro invocations in the beginning, can be adapted to be elastic mode compatible using certain (experimental) APIs provided in the JuliaHub environment. Essentially it involves using the @init_workers macro provided in the JuliaRunJob.Elastic module instead of @everywhere. E.g.:
using Main.JuliaRunJob.Elastic
Elastic.@init_workers begin
function docalc(x)
# ...
x*10
end
endIf the program makes use of pmap, use the one provided in the JuliaRunJob.Elastic module instead. E.g.:
Elastic.pmap(a) do x
return docalc(x)
endOther Distributed APIs that accept a worker pool can also be used, by explicitly providing the elastic pool instance. The Elastic.pool() API provides a reference to the elastic worker pool.
Logging
While running your job, live logs are available. Note that it can take a few minutes to launch the machines (longer for GPU machines). The logs are searchable through dynamic filters, with additional information available if you use the builtin [logging] module and related macros (like @info, @warn, and friends).
Preferences and Payments
The "Preferences" and "Payments" pages for the account can be accessed by clicking on the account settings icon in the upper right corner of the screen.
The menu can also be used to toggle between a light and dark theme for the web interface.
Secrets
Jobs can have access to secrets. Secrets can store sensitive information encrypted and make them available to your job at run time. This is available for use only in batch jobs as of now.
Secrets can be configured on the account preferences page. The secrets management section will list existing secrets if any are configured.
Secrets are associated with namespaces. The default namespace of a regular user is the email id with which they logged in. One may see other namespaces corresponding to groups that they belong to. A secret created with a group namespace is accessible to all users who belong to that group. Note that group members will have both read and write access to secrets in the group.
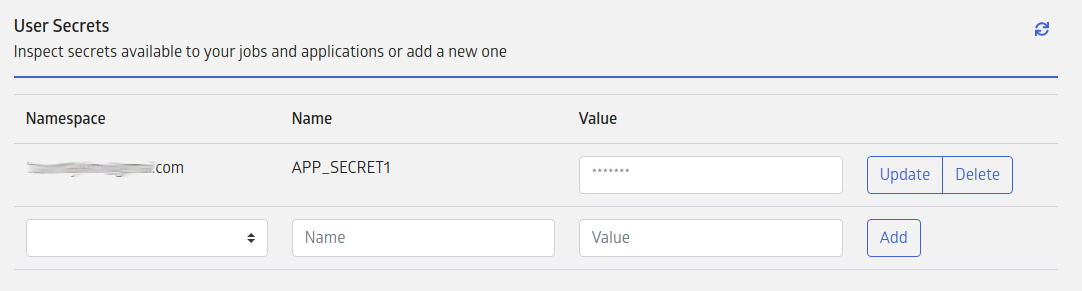
In the Job environment, secrets from the user's own namespace can be accessed in jobs using the intuitive get_secret API: secretvalue = JuliaRunJob.get_secret(secretname).
There is also a secrets manager get API that can be used to access secrets from other namespaces a user may have access to when the user belongs to any group:
secretvalue = JuliaRunJob.get(
JuliaRunJob.SECRETS_MANAGER[],
joinpath(base64encode(secrets_namespace), secretname)
)Where:
SECRETS_MANAGER[]provides a handle to the secrets manager context for the jobsecretnameis the name of the secret to accesssecrets_namespaceis the namespace in which the secret exists
It is important to note that these APIs are currently not supported for Julia IDE jobs, thus they cannot be called in VS Code. Users can use these APIs in Julia code, which can then be submitted as input for Standard Batch jobs.
Billing
Set your credit card information in the Payments settings:
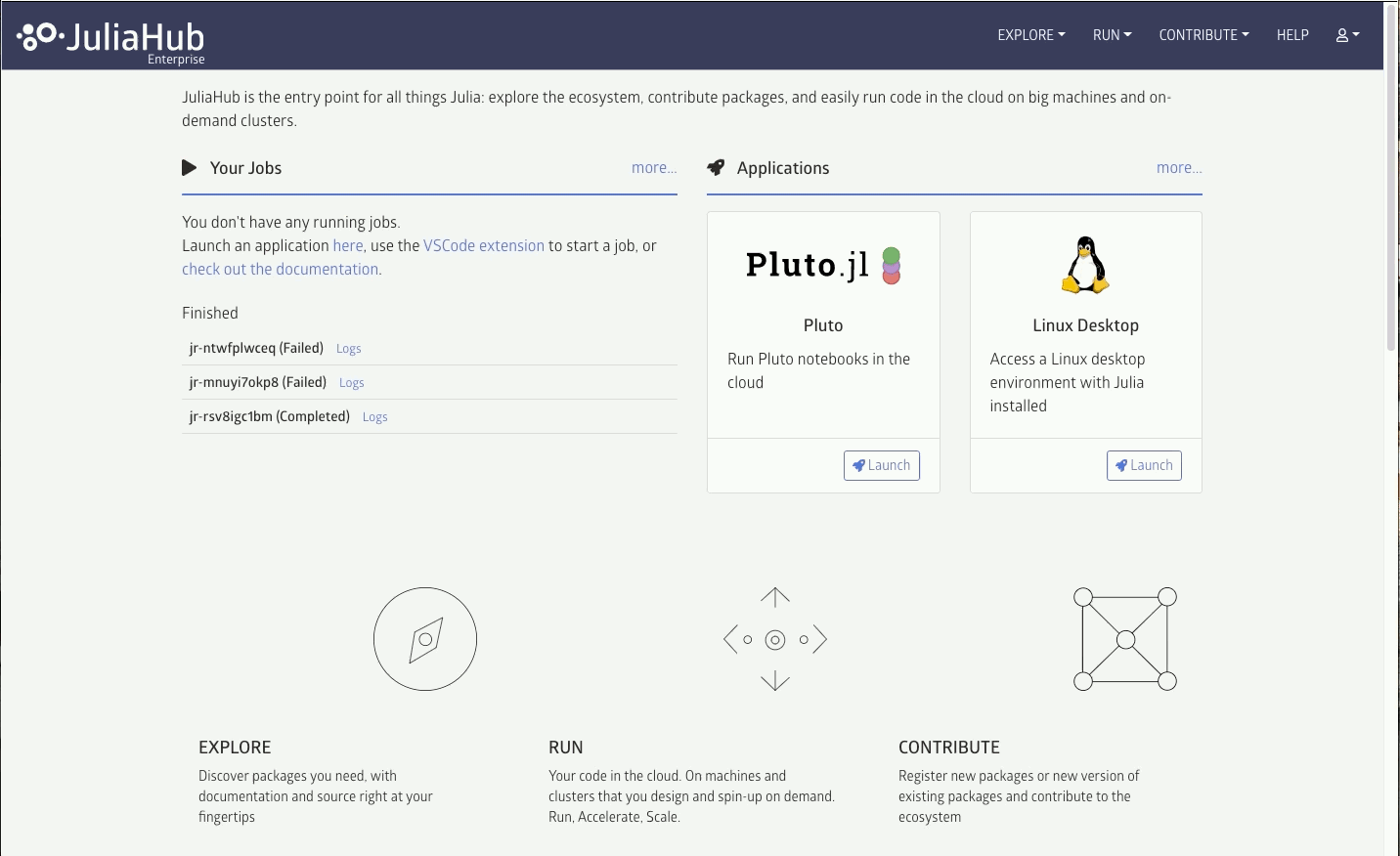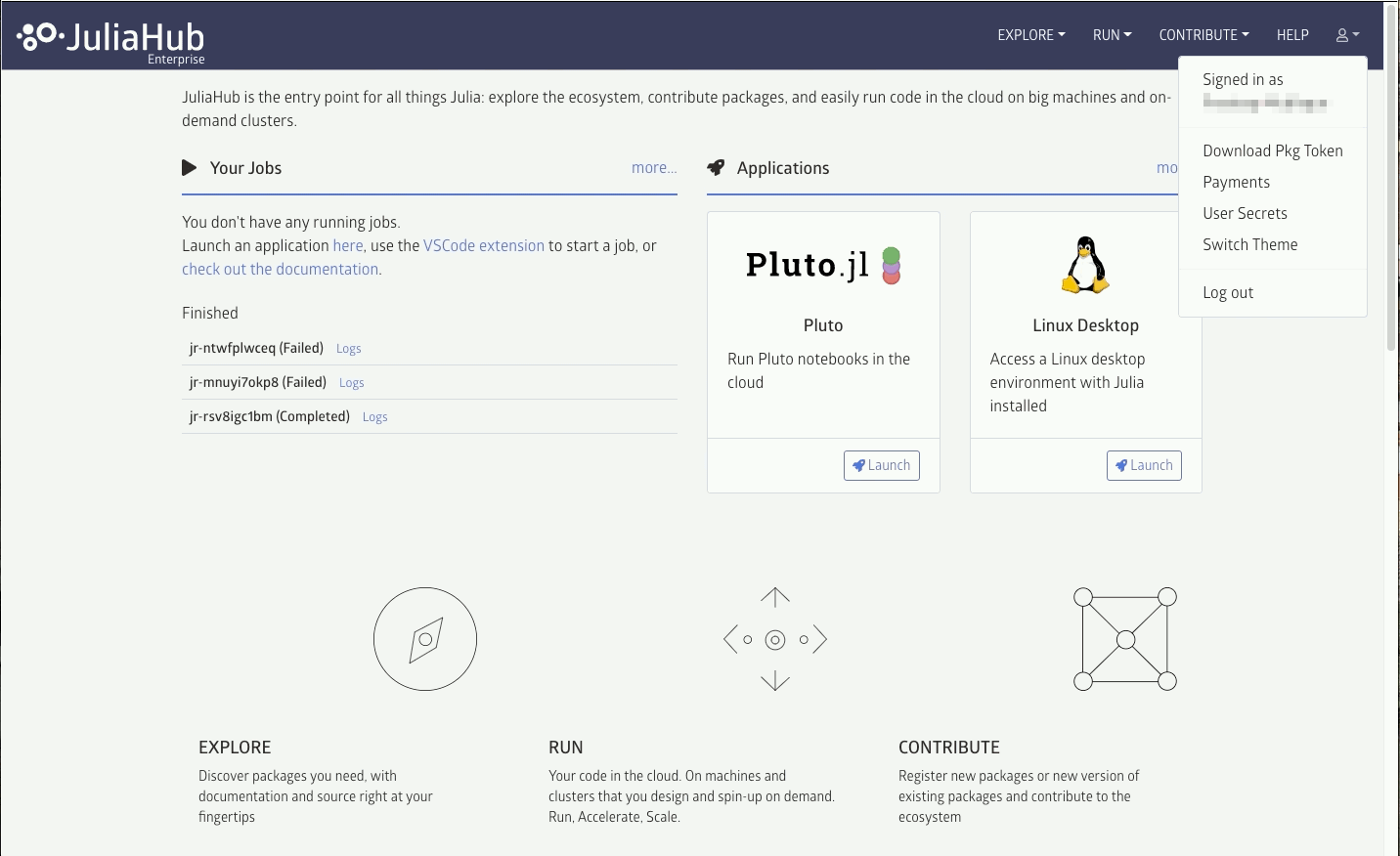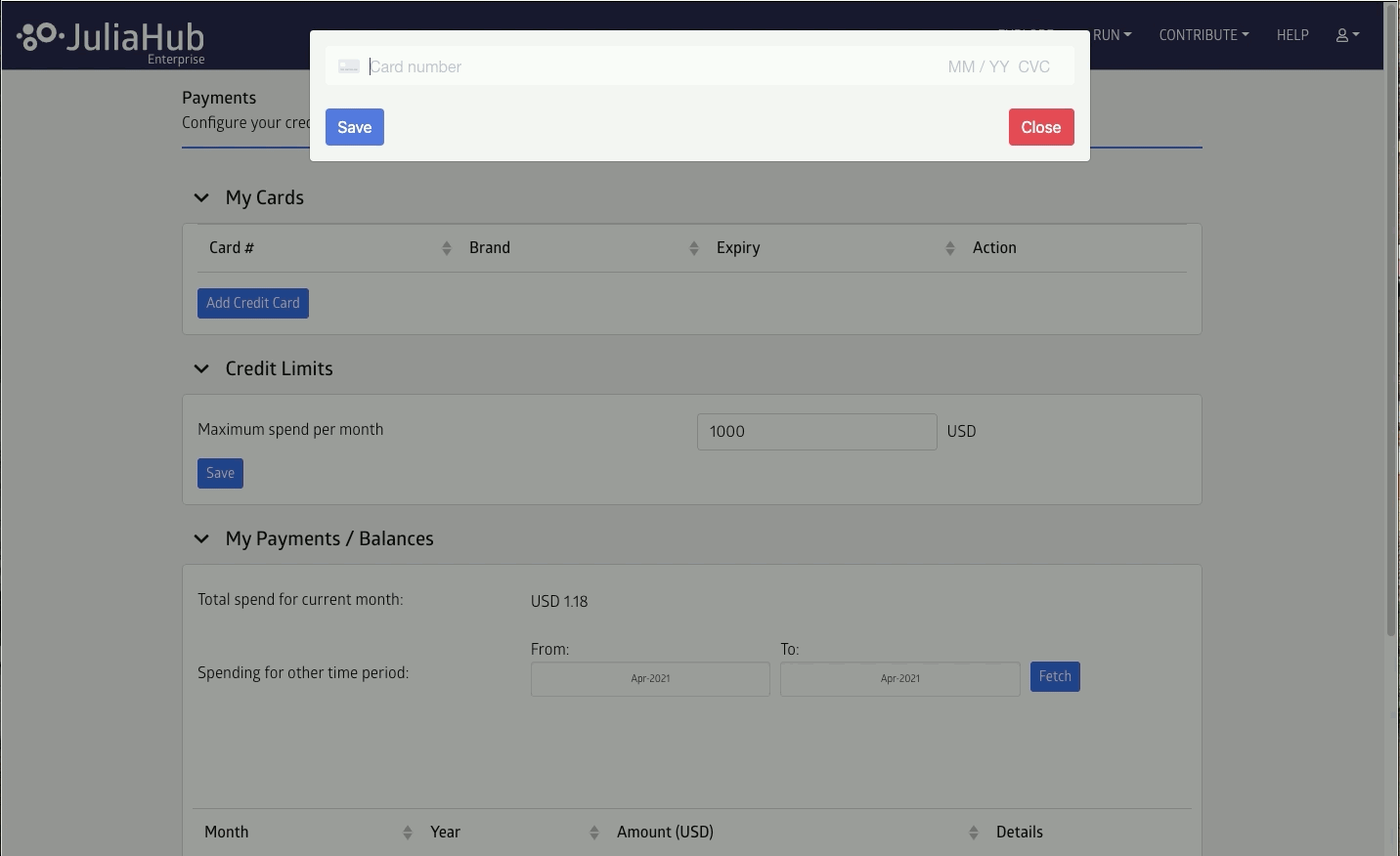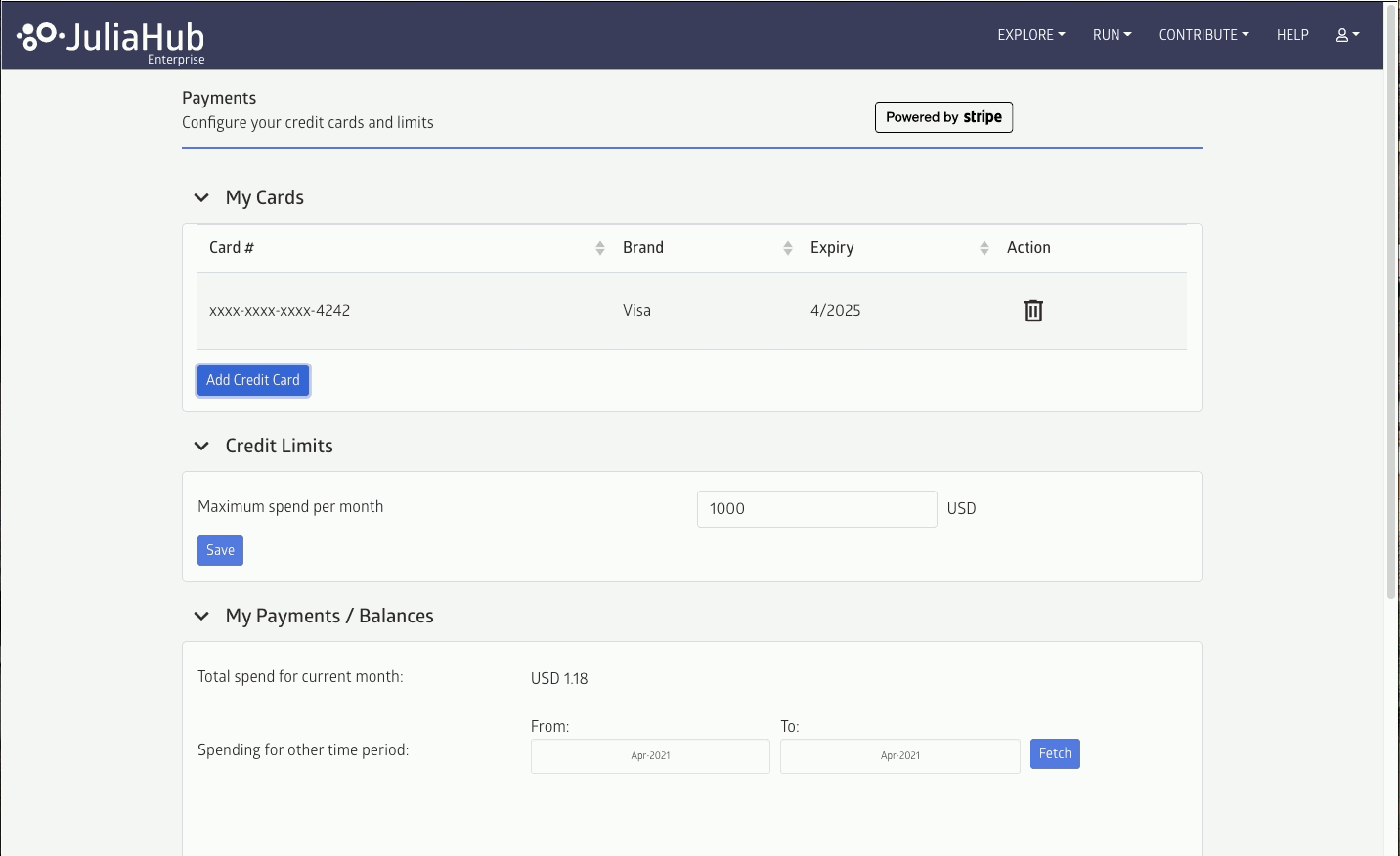
Billing is done at per-second interval, but with a minimum 10 minutes per job. You may set the maximum time or cost for any given job, but note that jobs that exceed that limit will be killed without storing any outputs (although logs will still be available).
Users and Groups
A JuliaHub user represents an authenticated entity that can access JuliaHub resources. Users are authenticated via an identity provider, which must be configured during installation to be able to use JuliaHub. The identity provider is usually owned by the enterprise where the installation exists.
Authorization for JuliaHub resources can be configured for authenticated users. They can also be configured for groups of users. Groups are simple collections of users. Nesting of groups is not possible. A user can be a member of multiple groups.
Groups can come from multiple sources, which are also sometimes called "realms". The enterprise identity provider can be a source or realm. This is referred to as the "site" or "IDP" realm in JuliaHub. There also exists a JuliaHub internal realm, which comes with certain pre-defined groups - "admins", "customeradmins" (business admins), "users" and "anon". This is referred to as the "juliahub" realm. All authenticated users are automatically members of the "users" group in the "juliahub" realm. A user can not be un-assigned from the "users" group. Any unauthenticated access is treated as being done by the "anon" group. From authorizations perspective, any authorization granted to the "anon" group is applicable to all, while any authorization granted to the "users" group is applicable to all authenticated users.
Users and Groups Administration
Actions that can be performed on users and groups and their memberships are available in the "Users and Groups" section of the administration user interface. This section is only available to users who have the "admins" or "customeradmins" (business admins) group membership.
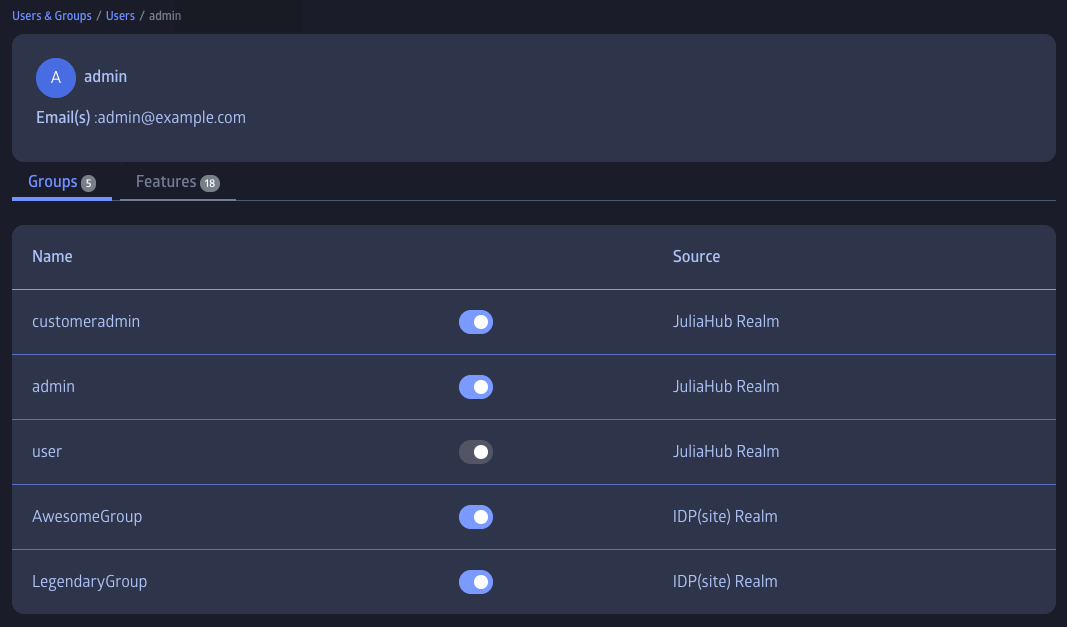
The "admins" are allowed to perform all actions. Only admins can assign users to the "admin" group. Customer admins can assign users to the "customeradmins" (business admins) group and any other group that is part of the "site" realm, but are not allowed to do any manipulations that refer to the "admin" group.
While certain JuliaHub features are accessible to all users, some may require authorization. The "Users and Groups" administration section also allows admins and customer admins to assign features to individual users.
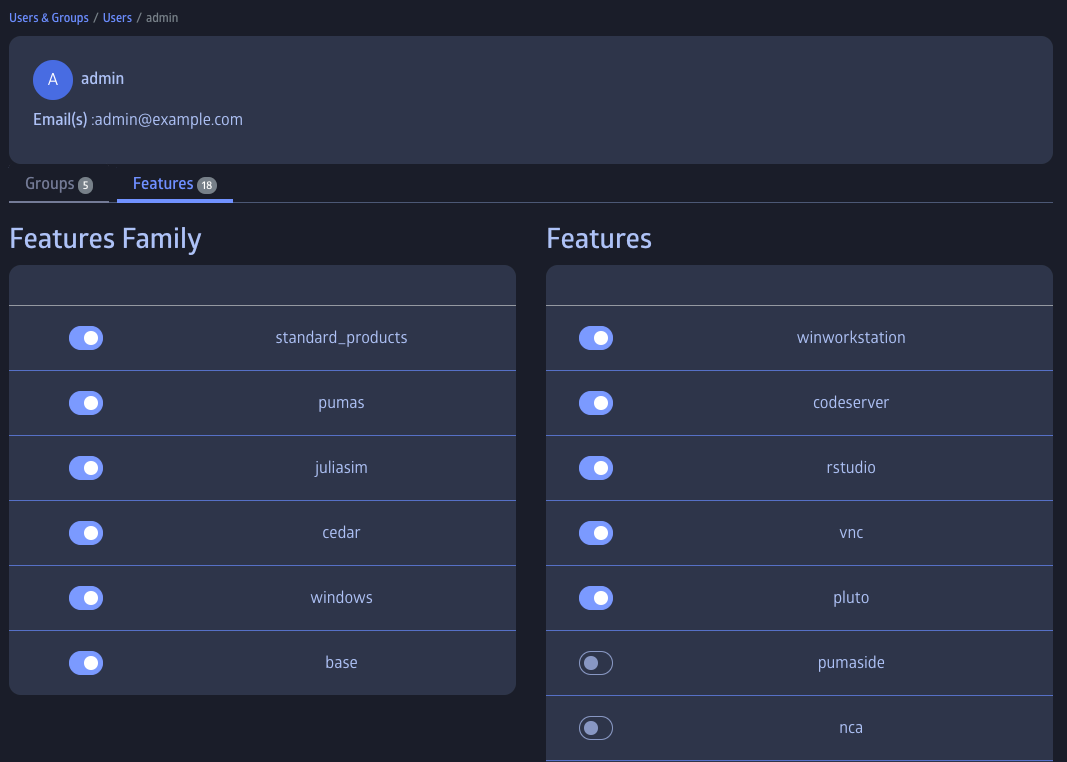
Permissions for users and admins
Here's a brief reference table of actions which users and administrators can perform, according to the JuliaHub specification v2.0:
| JuliaHub Platform Action | User | Administrator |
|---|---|---|
| Access platform | Yes | Yes |
| View Julia packages and applications | Yes | Yes |
| Search documentation | Yes | Yes |
| Compute job support | Yes | Yes |
| Start interactive jobs | Yes | Yes |
| Start distributed jobs | Yes | Yes |
| Stop running jobs started by the user themself | Yes | Yes |
| Stop running jobs started by other users | No | No |
| Extend timeout of running jobs started by the user themself | Yes | Yes |
| Extend timeout of running jobs started by other users | No | No |
| View job history of jobs started by the user themself | Yes | Yes |
| View job history of jobs started by other users | No | No |
| Download job logs and results of job started by the user themself | Yes | Yes |
| Download job logs and results of job started by other users | No | No |
| Dataset support | Yes | Yes |
| Upload datasets | Yes | Yes |
| View storage metadata for datasets uploaded by the user themself | Yes | Yes |
| View storage metadata for datasets uploaded by other users | No | No |
| View and access uploaded datasets marked public | Yes | Yes |
| View and access uploaded datasets marked private and uploaded by the user themself | Yes | Yes |
| View and access uploaded datasets marked private and uploaded by other users | No | No |
| Delete datasets uploaded by the user themself | Yes | Yes |
| Delete datasets uploaded by other users | No | No |
| Change dataset visibility for datasets uploaded by the user themself | Yes | Yes |
| Change dataset visibility for datasets uploaded by other users | No | No |
| View Julia package usage for all users | No | Yes |
| View platform audit logs | No | Yes |
| View platform job usage summary | No | Yes |
| View Julia package analytics | No | Yes |
| Modify JuliaHub Platform configuration such as: | No | No |
| - Logo | No | No |
| - Notebook pinning | No | No |
| - Customizing home page | No | No |
| - Default machine configuration | No | No |
| - Default timeout | No | No |
| - Managing private Julia package registries | No | No |
| - Customize Project editing workflow options and default | No | No |
| Manage platform policy: create, modify, delete | No | Yes |
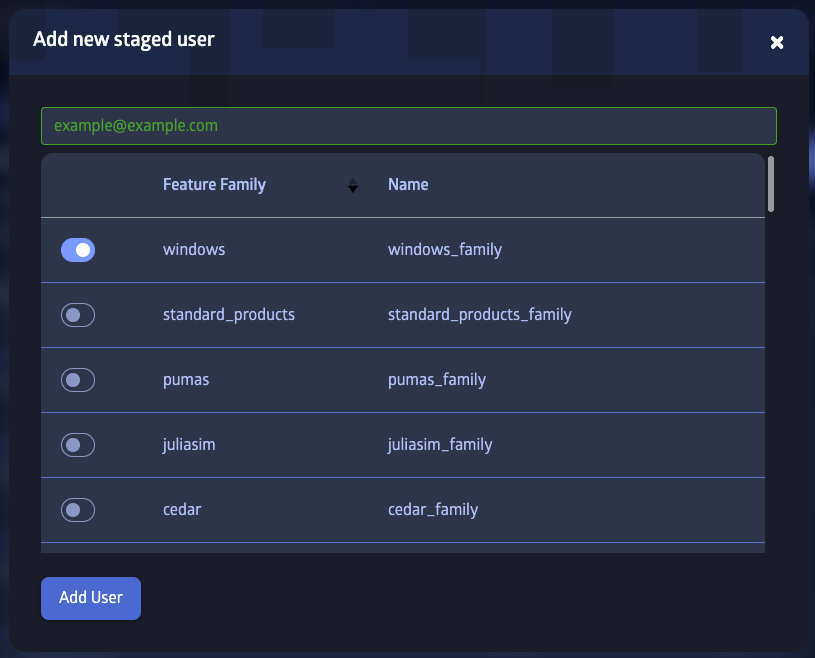
Staged Users
Staged users are users who have been invited to join JuliaHub but have not yet accepted the invitation. They are assigned special placeholder accounts, which let admins and customer admins pre-configure their accounts to a certain extent, e.g. staged accounts can be preconfigured with access to features. Staged users are not allowed to access JuliaHub resources. They can be deleted by admins or customer admins before they join. A staged user gets promoted to a regular user when they accept the invitation and log in to JuliaHub the first time. Regular users can not be deleted, so any resources associated with them and remains available in the system even if they can not log in to JuliaHub.
The "Users and Groups" section of the administration user interface allows admins and customer admins to create and manage staged users.
Programmatic Authentication
In order to communicate with the JuliaHub backend servers (e.g. to access datasets), a Julia session must have access to a user-specific authentication token. For this, JuliaHub reuses Julia's built-in support for authenticating with a package server.
In order for this to work, Julia must be configured to use the JuliaHub package server, and an auth.toml file, containing the user-specific authentication token, must be present in the ~/.julia directory.
In the different JuliaHub applications, this is generally all set up automatically. However, to access JuliaHub from external machines, this can be configured manually by
- Downloading the
auth.tomlfile from the preference page on JuliaHub and saving it to.julia/servers/juliahub.com/auth.toml.

- Configuring Julia to use the JuliaHub package server at
https://juliahub.com/(e.g. by settingJULIA_PKG_SERVERasJULIA_PKG_SERVER="https://juliahub.com/", or directly in the JuliaHub VSCode IDE plugin).
Note that the token in auth.toml expires in 24 hours if it is not used, and must be downloaded again. However, any operation in the Julia package manager that talks to the package server (like updating a package or the registry) will refresh the token automatically.
Connecting VSCode IDE to JuliaHub
Make sure you've got the main Julia plugin installed from the VSCode marketplace as discussed in the vscode Julia extension documentation.
Next, install the JuliaHub plugin from the VSCode marketplace. Once installed, use the "show JuliaHub" command to open the JuliaHub pane.
The JuliaHub plugin uses the package server setting from the Julia plugin. You'll need to set this to https://juliahub.com:
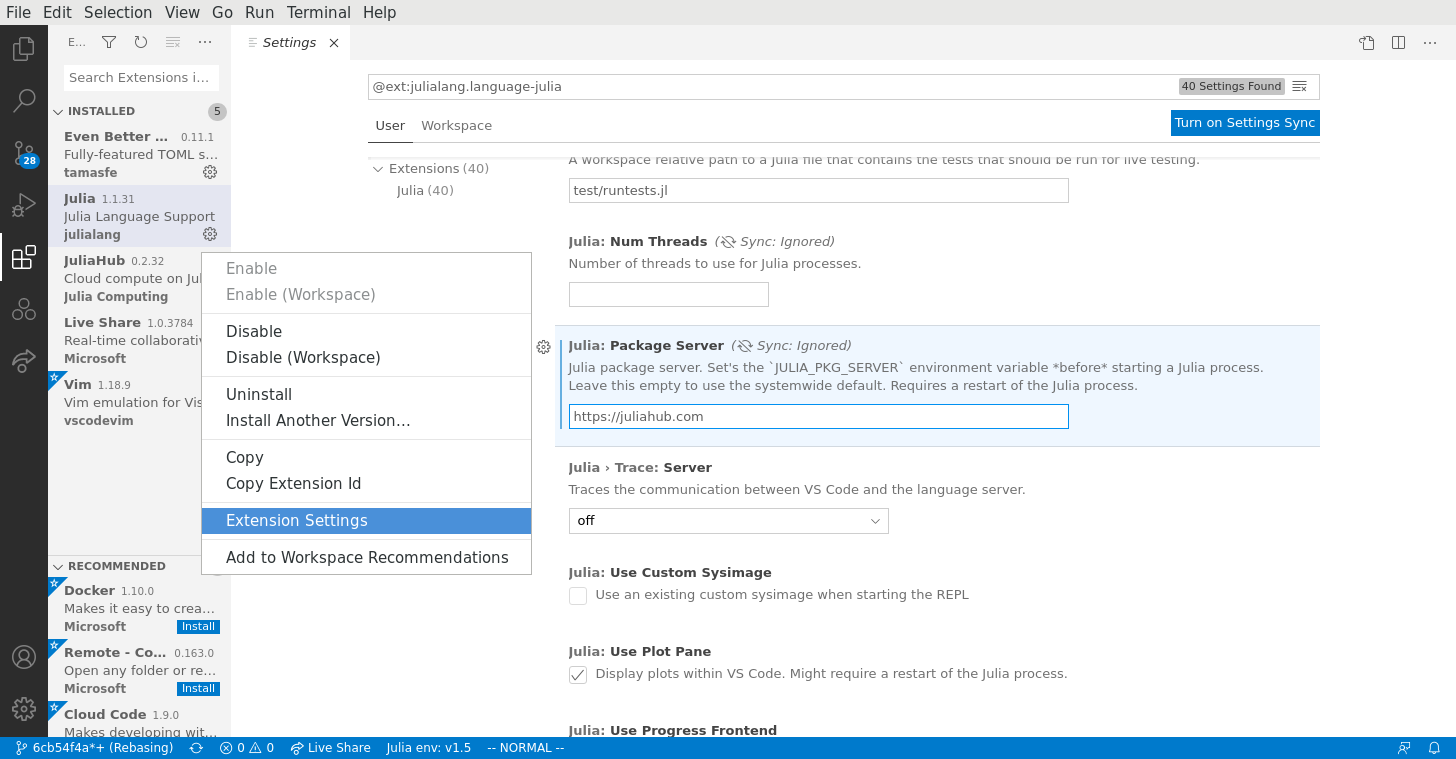
If need be, the VSCode plugin will open a browser window to authenticate with JuliaHub and then automatically acquire the auth.toml file.